
Why Field Standardization Matters for AI Data Quality

TL;DR:
- Field standardization ensures consistent field names, data types, and semantics across AI datasets to prevent data quality issues. It reduces costs by avoiding silent schema divergence, streamlining validation, and lowering incident response times. Implementing a disciplined governance cycle with versioned ownership and automation sustains durable, trustworthy data for AI systems.
Field standardization is the practice of defining consistent field names, data types, formats, and semantics across every dataset your AI systems consume. Without it, your training data is a liability. Inconsistent schemas corrupt model inputs, inflate annotation costs, and make debugging a manual, time-consuming process. Organizations like GitLab, MLCommons, and the UK government have each published concrete evidence that field-level consistency is the foundation of trustworthy AI, not an optional cleanup task. If you are evaluating your data pipeline’s readiness for production AI, why field standardization exists as a discipline is the right question to start with.
Why field standardization is critical for AI data quality
Field standardization prevents what data engineers call “definition drift,” the gradual divergence in how the same concept gets recorded across teams, tools, and time. A field named "user_idin one pipeline becomesuserIdin another anduid` in a third. The result is broken joins, silent data loss, and model features that mean different things depending on which upstream source fed them.

The UK government’s 2026 AI readiness guidance defines data quality dimensions as accuracy, completeness, consistency, timeliness, validity, and uniqueness. Every one of those dimensions depends on fields being defined the same way at the point of collection and at the point of consumption. A dataset that scores well on accuracy but poorly on consistency will still produce unreliable model outputs.
Consistent schemas also make validation rules enforceable. When every record in a dataset uses the same field structure, you can run automated checks at ingestion: type validation, range checks, null rate thresholds. Without standardized fields, each validation rule becomes a bespoke script written for one source, which multiplies maintenance overhead as your data volume grows.
- Accuracy: Standardized fields allow range and format checks to catch errors at ingestion rather than during training.
- Consistency: Uniform naming eliminates silent mismatches when joining datasets from multiple sources.
- Completeness: Defined required fields make null detection systematic rather than ad hoc.
- Auditability: Consistent field semantics create auditable evidence that regulators and internal governance teams can verify.
Pro Tip: Integrate your field specification directly into your Data Quality Action Plan (DQAP) so that live quality metrics flag deviations from the standard automatically, rather than relying on periodic manual audits.
What are the operational and business benefits of enforcing field standards?
The financial case for standardization is not abstract. Poor data quality costs large enterprises an estimated $12.9 million annually, according to Gartner research. That figure covers rework, failed analytics projects, and delayed model deployments. It does not capture the opportunity cost of decisions made on corrupted data.
GitLab’s observability team documented a more specific operational impact. Inconsistent field names force engineers to write bespoke queries for every incident investigation, which directly increases mean time to recovery (MTTR). When the same event field is named differently across services, on-call engineers spend the first 20 minutes of an incident just locating the right data. GitLab resolved this by creating a single source of truth field specification distributed through shared libraries in Go, Ruby, and Rust.
The operational benefits compound over time:
- Fewer bespoke queries: Standardized fields mean analysts write one query pattern that works across all data sources, not one per source.
- Lower MTTR: Incident responders find the right fields immediately because naming is predictable.
- Simplified pipelines: ETL jobs require fewer transformation steps when source and destination schemas already align.
- Reduced annotation rework: Labeling teams work faster when field definitions are unambiguous and documented upfront.
For ML Engineering Managers, the downstream effect is equally significant. Standardized training data reduces the time your team spends on data management challenges before a single model training run begins. That time compounds across every experiment cycle.
How do contemporary standards and governance models support field standardization?
Effective governance is what separates a one-time cleanup from a durable standard. Two frameworks illustrate what mature field governance looks like in practice.
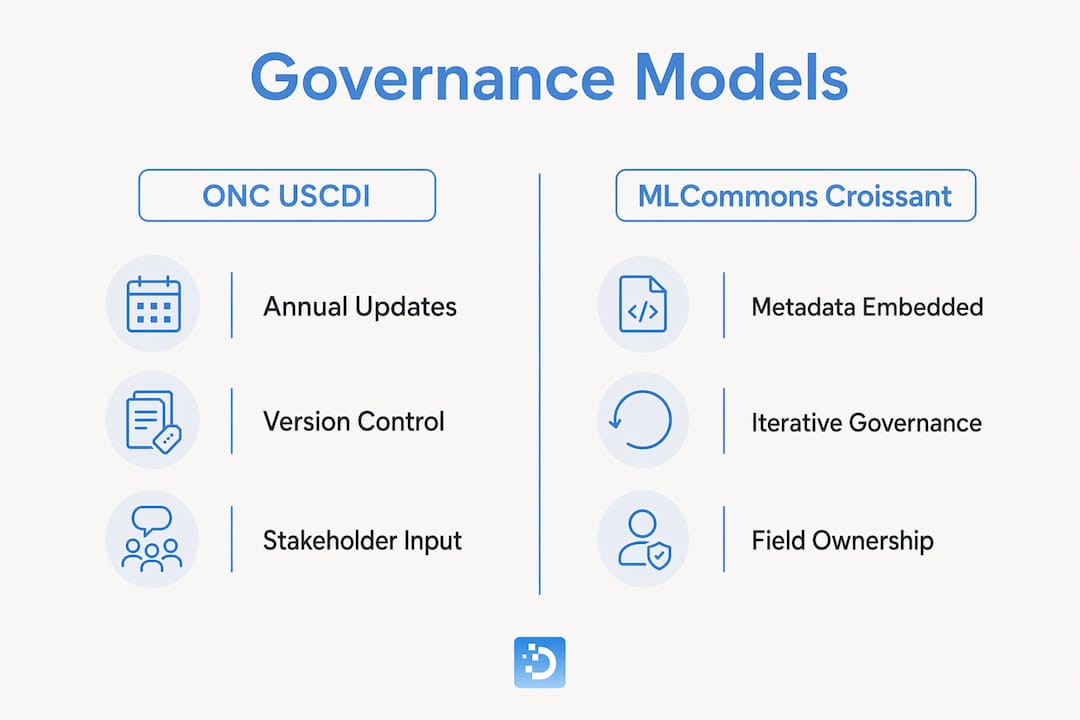
The Office of the National Coordinator for Health Information Technology (ONC) updates its United States Core Data for Interoperability (USCDI) standard on an annual cadence. Draft USCDI v7 proposed 30 new or revised data elements in 2026, with the draft published in January and the final version released in July. This structured cycle gives implementers a predictable window to review changes, provide feedback, and update their systems before the new version takes effect. The lesson for AI teams is that field standards require a governance cadence, not a one-time definition.
MLCommons’ Croissant 1.1 takes a different approach, embedding governance directly into dataset metadata. Croissant 1.1 adds structured usage policy tags, machine-actionable provenance records, and multi-dimensional dataset support. This means an AI agent or automated pipeline can read a dataset’s field definitions, understand its permitted uses, and validate its provenance without human intervention. That is the practical end state of field standardization: governance that runs itself.
The following comparison shows how these two models differ in approach:
| Governance model | Update cadence | Key mechanism | Best suited for |
|---|---|---|---|
| ONC USCDI | Annual (Jan draft, Jul final) | Stakeholder feedback and versioned releases | Regulated industries, interoperability |
| MLCommons Croissant 1.1 | Continuous via metadata tags | Machine-actionable schema and provenance | AI training data, automated pipelines |
Both models share three core principles: versioning, backwards compatibility, and stakeholder input before changes are finalized.
Pro Tip: When designing your field governance process, assign a named owner to each field in your specification. Ownerless fields drift silently. Named owners create accountability for keeping definitions current.
What are practical steps for implementing field standardization?
Implementing field standardization effectively requires working at three levels simultaneously: structural, semantic, and operational lifecycle.
-
Define a single source of truth specification. Document every field name, data type, accepted values, and semantic definition in one place. GitLab’s LabKit spec is a concrete example. Distribute this specification through shared libraries so developers consume the standard rather than redefine it.
-
Layer semantic standards onto structural ones. Structural consistency (field names and types) is necessary but not sufficient. Semantic standards define what a field means. The Croissant 1.1 blueprint combines schema definitions with vocabulary interoperability tags so that fields carry meaning across different systems and organizations.
-
Implement continuous validation. Build automated checks that compare incoming data against your field specification at ingestion. The UK government’s DQAP framework recommends live quality monitoring with metrics tracked in real time, not in weekly batch reports.
-
Use feature flags for migrations. When you update a field definition, run the old and new versions in parallel using feature flags. This preserves backwards compatibility while you validate that downstream consumers handle the new format correctly.
-
Establish a governance cadence. Schedule quarterly reviews of your field specification. Collect feedback from data consumers, annotation teams, and model engineers. Treat your field standard as a living document with a version history, not a static artifact.
Pro Tip: Build your machine-ready dataset requirements into your field specification from day one. Retrofitting standardization onto an existing pipeline costs three to five times more than designing it in at the start.
Key takeaways
Field standardization is the single most cost-effective investment an AI team can make before scaling its data pipeline, because every downstream quality problem traces back to an upstream definition failure.
| Point | Details |
|---|---|
| Definition drift is the core risk | Inconsistent field names across sources silently corrupt joins, features, and model inputs. |
| Financial cost is quantifiable | Poor data quality costs enterprises an estimated $12.9M annually, per Gartner research. |
| Governance requires a cadence | Standards like ONC USCDI update annually; your internal spec needs the same discipline. |
| Automation depends on standardization | Croissant 1.1 shows that machine-actionable governance only works when fields are consistently defined. |
| Single source of truth reduces MTTR | GitLab’s shared field libraries cut incident recovery time by eliminating bespoke query writing. |
Field standardization is a discipline, not a project
I have seen ML teams treat field standardization as a one-sprint cleanup task. They align field names, write a wiki page, and move on. Six months later, a new data source gets onboarded by a different team, the wiki is stale, and the drift starts again.
The teams that get this right treat their field specification the way a software team treats an API contract. It is versioned, owned, tested, and updated on a schedule. GitLab’s approach of distributing the spec through shared libraries is the right model because it makes compliance the path of least resistance. Developers do not have to remember the standard; they just use the library.
The UK government’s framing of datasets as strategic products with ownership and quality obligations is equally instructive. A dataset without a named owner is a dataset that will drift. Assign ownership, set a review cadence, and connect your field spec to your quality monitoring. That combination is what makes standardization durable rather than decorative.
The cost of getting this wrong is not just a messy schema. It is corrupted training data, failed model deployments, and incident response time that compounds every quarter. The investment in getting it right pays back faster than most teams expect.
— Oleg
How DOT Data Labs delivers standardized, production-ready training data

DOT Data Labs builds AI training datasets with field standardization designed in from the start, not bolted on after collection. Every dataset DOT Data Labs delivers follows a defined schema specification, validated at ingestion and verified before final delivery. Whether you need a one-off custom dataset, an off-the-shelf corpus, or an ongoing data pipeline, the output arrives in a consistent, model-ready format your team can use without a cleanup sprint. Check your dataset’s quality readiness with the AI data quality checklist before your next training run, or explore DOT Data Labs’ full range of custom AI training data services to see how standardized data delivery works at scale.
FAQ
What is field standardization in AI and machine learning?
Field standardization is the practice of defining consistent field names, data types, formats, and semantics across all datasets used in AI workflows. It prevents definition drift and ensures that data from multiple sources can be joined, validated, and consumed by models without transformation errors.
Why is standardization necessary for AI training data?
Unstandardized fields produce silent data quality failures: broken joins, mismatched features, and corrupted model inputs. The UK government’s AI readiness guidance identifies consistency as one of six core data quality dimensions required for AI-ready datasets.
How does field standardization reduce operational costs?
Consistent field definitions eliminate bespoke query writing during incident response, as documented by GitLab’s observability team, and address the root cause of poor data quality that costs enterprises an estimated $12.9 million annually per Gartner.
What is the best way to maintain field standards over time?
Assign named ownership to every field, distribute your specification through shared libraries, and establish a quarterly review cadence. The ONC USCDI model, which publishes a draft in January and a final version in July each year, demonstrates how structured update cycles keep standards current without breaking existing implementations.
How does Croissant 1.1 support field standardization?
MLCommons’ Croissant 1.1 embeds machine-actionable provenance records, usage policy tags, and vocabulary interoperability directly into dataset metadata, enabling automated governance pipelines to validate field definitions without human intervention.