
The Role of Clean Data in AI Model Performance

TL;DR:
- Clean data is the foundational variable that determines AI model reliability and performance in production. Prioritizing continuous data quality monitoring and governance outperforms model architecture tuning in delivering sustained AI success.
Most AI teams spend months debating model architecture while their training data quietly undermines everything. The role of clean data in AI is not a preprocessing concern you hand off to a junior engineer. It is the foundational variable that determines whether your model ships reliably or degrades in production. 73% of enterprise data leaders rank data quality as their top AI challenge, ahead of compute costs and model selection. If you are optimizing the wrong variable, no amount of hyperparameter tuning will save you.
Key Takeaways
| Point | Details |
|---|---|
| Clean data beats model complexity | Fixing label noise in a simple model can outperform a complex model trained on dirty data. |
| Hallucinations trace back to data | Structural noise in training data makes LLMs 3.5x more likely to hallucinate outputs. |
| One-time cleaning is insufficient | 91% of deployed models degrade within months without continuous data quality monitoring. |
| Governance is not optional | Without data lineage and auditability, AI systems face serious regulatory exposure under frameworks like the EU AI Act. |
| Data investment outperforms model tuning | Leading AI organizations invest four times more in foundational data governance than in model tuning. |
The role of clean data in AI, defined
Clean data is not simply data without typos. In an AI context, it means data that is accurate, complete, consistent, representative of the problem distribution, and free from structural artifacts that corrupt model learning. The ISO/IEC 5259 standard for AI data quality codifies these characteristics formally, and they matter because violations in any dimension compound during training.
The most common data quality failures in AI datasets include:
- Label noise: Incorrect or inconsistent annotations that teach models the wrong signal. Label errors average 3.4% across major ML benchmarks, and even ImageNet’s validation set contained over 2,900 mislabeled examples.
- Missing data: Gaps in feature coverage that force models to learn from incomplete distributions, often producing biased predictions.
- Duplicates: Repeated records that artificially inflate the apparent frequency of certain patterns, skewing model behavior toward over-represented cases.
- Distributional mismatch: Training data that does not reflect real-world inference conditions, which is one of the primary drivers of production failure.
The downstream effects are not subtle. Biased outputs, performance degradation under distribution shift, and hallucinations in generative models all trace directly to data quality failures. The importance of clean data in AI is not a theoretical concern. It is the difference between a model that works in a notebook and one that holds up in production.
Measurable impact on AI project outcomes
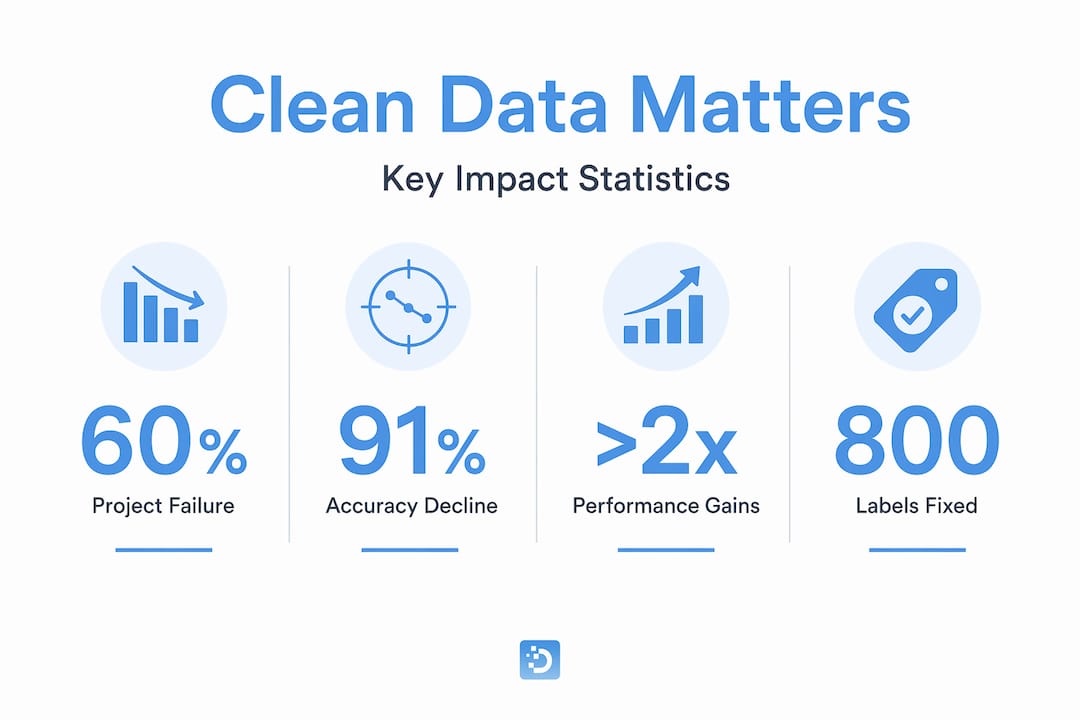
The research on the impact of data quality on AI is blunt. Gartner projects that 60% of AI projects lacking AI-ready data will be abandoned by 2026. That is not a warning about model selection. It is a warning about data.
The performance gains from cleaning data are often larger than what teams achieve from switching architectures. Consider the label quality case: cleaning 800 mislabeled examples from a dataset enabled ResNet-18 to exceed ResNet-50 accuracy, moving from 0.77 to 0.82 on the benchmark. A smaller, simpler model outperformed a larger one purely because its training data was cleaner.

The same pattern holds in generative AI. Pages with poor structural quality are 3.5x more likely to cause hallucinations in LLMs. After targeted remediation of structural noise, mean hallucination rates dropped from 0.41 to 0.15. That is a 63% reduction, achieved without changing the model architecture at all.
| Intervention | Before | After | Improvement |
|---|---|---|---|
| Label cleaning (ResNet-18 vs ResNet-50) | 0.77 accuracy | 0.82 accuracy | +6.5% |
| Structural data remediation (LLM hallucinations) | 0.41 rate | 0.15 rate | 63% reduction |
| Continuous quality monitoring (model longevity) | Degrades in months | Sustained performance | Avoids 91% failure rate |
“Data-centric AI shifts the focus from model fixes to improving datasets for more sustained and reliable AI performance.” — Science Reader
These numbers reframe how you should be allocating engineering time. If your model is underperforming, the first audit should be your data, not your architecture.
Clean data strategies for AI pipelines
How clean data boosts AI is only half the question. The other half is how you maintain it at scale. The teams that get this right treat data cleaning as a continuous engineering discipline, not a one-time preprocessing step before training.
Here is how that looks in practice:
- Integrate quality gates into your ML pipeline. Automated quality gates and policy-as-code block poor-quality data from progressing through the pipeline before it reaches training. This is the equivalent of unit tests for your data, enforced at every stage rather than reviewed manually at the end.
- Track metadata and data lineage actively. Knowing where each data point originated, how it was transformed, and who labeled it is not just a compliance requirement. It is how you debug model failures that trace back to upstream data issues.
- Monitor for schema drift and label distribution shifts. Production data distributions change. Building monitoring that flags when incoming data diverges from the training distribution gives you advance warning before accuracy degrades.
- Audit confidence scores and label consistency regularly. Interpretation drift, where a model sustains accuracy but shifts its internal reasoning, can be caught through periodic confidence audits on held-out evaluation sets. Stable accuracy does not mean stable behavior.
- Validate annotations with inter-annotator agreement metrics. For human-labeled datasets, disagreement rates above 10-15% on subjective tasks are a signal that your labeling guidelines need revision before you train on that data.
Pro Tip: Build your data preprocessing workflow with the assumption that every external data source will contain errors. Validation logic is cheaper to write upfront than to retrofit after a model has already been trained on corrupted data.
Governance, trade-offs, and the quantity-vs-quality debate
More data is not always better data. This is one of the most persistent misconceptions in applied ML. A 10-million-sample dataset with 5% label error introduces 500,000 corrupted training examples. A 1-million-sample dataset with 0.5% label error is often the stronger choice, even though it is one-tenth the size.
The core trade-offs and complexities worth keeping in mind:
- Governance as infrastructure. Without data lineage, provenance, and auditability, AI systems operate as black boxes. Under the EU AI Act and similar frameworks, this creates direct regulatory exposure, not just technical debt.
- Interpretation drift. Models can maintain accuracy metrics while changing their internal reasoning unpredictably due to noise. In high-stakes domains like healthcare diagnostics or financial risk scoring, this is a serious problem that stable accuracy numbers will not reveal.
- Synthetic data as a supplement. Synthetic data can fill distributional gaps and augment underrepresented classes, but it introduces its own quality risks if not carefully validated against real-world distributions before inclusion in training sets.
- Aligning data quality to business metrics. Not all data quality problems are equally costly. A labeling error in a low-stakes product recommendation is different from a labeling error in a medical device. Your quality investment should be proportional to the failure cost of your model.
A useful framing: treat your dataset as a product. It should have a spec, a validation suite, versioning, and an owner. Teams that apply product engineering discipline to their training data are the ones that ship AI systems that hold up beyond the demo.
My take: why most AI teams are solving the wrong problem
I’ve watched teams burn six months on architecture experiments while sitting on training data they’ve never properly audited. The model-first mindset is seductive because models are tractable. You can run experiments, compare metrics, and feel productive. Data quality work is less glamorous and harder to measure in a sprint review.
But in my experience, the organizations that ship reliable AI systems invest heavily in treating data quality as a first-class engineering concern. They build it into CI/CD pipelines. They assign ownership. They version their datasets the way they version their code. The four-times higher effectiveness that data-centric organizations report over model-tuning-focused teams is not surprising to anyone who has seen both approaches up close.
The teams that keep losing are the ones that treat data cleaning as a one-time gate before training, then wonder why their model degrades three months after deployment. You cannot solve a data problem with a model fix. I have never seen it work. The discipline is continuous, and it needs to be built into the pipeline from day one.
— Oleg
How Dotdatalabs helps you get the data right

If your AI pipeline is only as good as the data feeding it, the sourcing and cleaning stage deserves the same rigor as your model development. Dotdatalabs handles the full data supply chain for ML teams, from raw collection and web scraping at scale through deduplication, human annotation, and quality validation, delivering model-ready training data without requiring you to manage multiple vendors or build internal tooling. Whether you need a one-off custom dataset built to your exact specifications or an ongoing pipeline that continuously feeds clean, labeled data into your training infrastructure, Dotdatalabs brings the annotation and labeling expertise needed to keep your models performing in production. Talk to the team about your data requirements.
FAQ
What is the role of clean data in AI?
Clean data directly determines how accurately and reliably an AI model learns. Errors, inconsistencies, and distributional gaps in training data cause bias, hallucinations, and performance degradation that no amount of model tuning can fully correct.
How does data quality affect AI model accuracy?
Even small rates of label noise compound at scale. Cleaning 800 mislabeled labels in one benchmark enabled a simpler model to outperform a more complex one, demonstrating that data quality can matter more than architecture choice.
Why do AI models degrade after deployment?
91% of deployed ML models see accuracy decline within months due to data shifts in production. Without continuous monitoring and quality management, model performance deteriorates as real-world data drifts from the training distribution.
What is interpretation drift in AI?
Interpretation drift occurs when a model maintains stable accuracy but changes its internal reasoning unpredictably due to underlying data noise. It is particularly risky in sensitive domains like healthcare or finance, where decision logic matters as much as output accuracy.
How can teams build clean data strategies for AI?
The most effective approach is treating data quality as a continuous process integrated into ML pipelines through automated quality gates, schema drift monitoring, and regular label audits, rather than a one-time preprocessing task before training begins.