
How to Format Training-Ready Data for AI Fine-Tuning

TL;DR:
- Proper data formatting ensures faster, more stable fine-tuning with better model performance.
- Cleaning and validating data, including PII removal and deduplication, are essential for quality datasets.
- Starting with small, high-quality datasets before scaling reduces noise and improves generalization.
Fine-tuning fails more often because of bad data formatting than bad model choices. Teams spend weeks selecting architectures, only to discover their datasets are misaligned, noisy, or structurally inconsistent with the target model’s expectations. Training-ready data means your examples are correctly structured, cleaned, validated, and schema-compliant before a single training step runs. This article walks you through every stage of that process: choosing the right format, cleaning your raw data, applying model-specific templates, and catching the pitfalls that quietly destroy generalization. Follow these steps and your fine-tuning runs will be faster, more stable, and far more likely to produce a model that actually performs.
Key Takeaways
| Point | Details |
|---|---|
| Use model-matched formats | Choose and validate the format (like JSONL) that fits your target LLM and fine-tuning process exactly. |
| Clean before formatting | Remove PII, deduplicate, and standardize data to improve downstream accuracy and safety. |
| Template alignment matters | Apply and validate model-specific templates to avoid failed fine-tunes and incoherent outputs. |
| Balance diversity and quality | Use diverse, high-quality samples and synthetic augmentation to improve robustness and reduce overfitting. |
| Start small, scale smart | Begin with a small, gold-quality set for validation before scaling to larger training runs. |
Understanding training-ready data formats
With a clear goal in mind, let’s begin by demystifying the various formats you’ll encounter in LLM fine-tuning.
Not all data formats are equal, and choosing the wrong one is one of the fastest ways to produce a broken training run. Primary formats for LLM fine-tuning are JSONL with structured chat messages, prompt-completion pairs, and raw text for continued pretraining. Each serves a different purpose, and picking the right one depends on your model, your task, and how much control you need over the conversation structure.
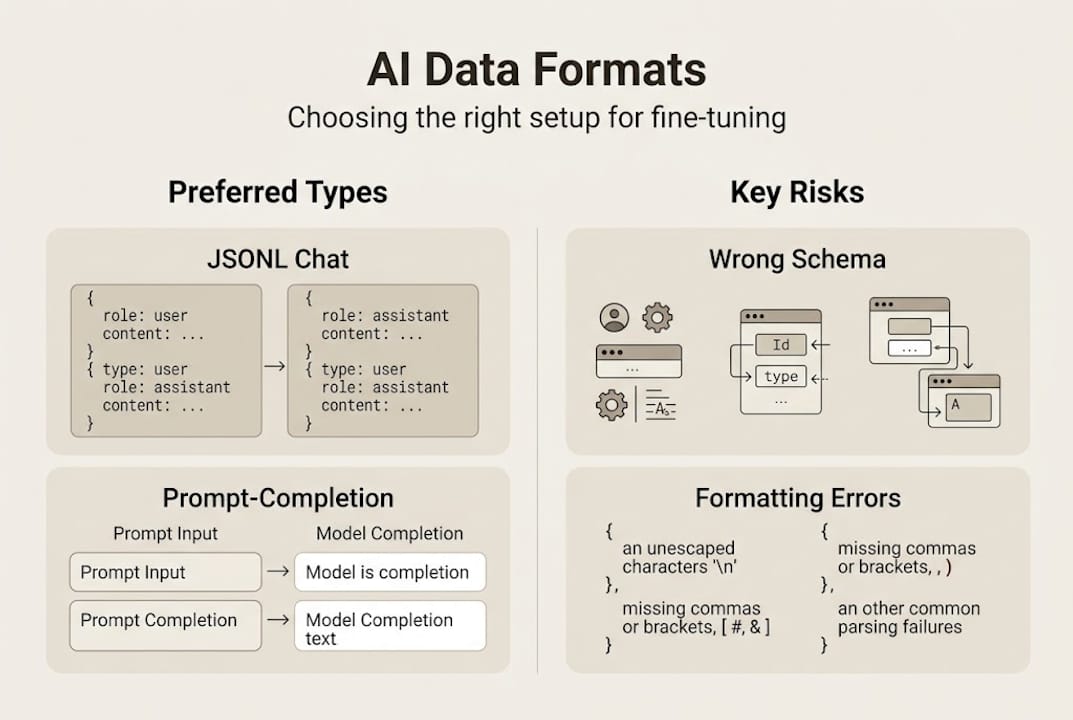
JSONL with chat messages is the dominant format for instruction-tuned models. Each line is a self-contained JSON object containing a list of role-tagged messages: system, user, and assistant. This mirrors how modern LLMs like GPT-4 and Llama 3 actually process conversations, making it the most natural fit for fine-tuning chat or instruction-following behavior.
Prompt-completion pairs work well for simpler supervised tasks where you want the model to learn a direct input-to-output mapping. Think classification, summarization, or extraction tasks where the conversation structure is unnecessary overhead.
Raw text is reserved for continued pretraining, where you want the model to absorb domain knowledge rather than learn a specific response pattern. Medical literature, legal documents, or proprietary technical manuals are common candidates.
Here is a quick comparison to help you decide:
| Format | Best for | Key requirement |
|---|---|---|
| JSONL chat messages | Instruction tuning, chat agents | Role tags, model chat template |
| Prompt-completion pairs | Classification, extraction, summarization | Consistent delimiter |
| Raw text | Domain pretraining | Clean, deduplicated corpus |
| CSV | Tabular ML tasks | Strict column schema |
For tabular machine learning tasks, CSV datasets best practices deserve their own attention since schema drift and missing values behave very differently than in text-based formats.
Why does format precision matter so much? Because clean, properly structured data improves model precision by 15 to 20% compared to loosely formatted alternatives. That gap compounds across epochs. A model trained on well-structured data converges faster and generalizes better. One trained on ambiguous or inconsistently formatted data learns noise as signal.
Key things to verify before you commit to a format:
- Does your target model have a mandatory chat template (Llama, Mistral, OpenAI)?
- Are your examples consistent in structure across every row or line?
- Have you confirmed the format matches the fine-tuning API or framework you are using?
- Is your schema documented so future dataset updates stay aligned?
Format is not a cosmetic choice. It is a structural contract between your data and your model.
Preparing and cleaning your dataset: Essential steps
Once you know your dataset’s format, the next priority is to ensure data quality through effective preparation.
Raw data is almost never training-ready. It contains duplicates, inconsistent casing, personally identifiable information, and noise that confuses the model. Data preparation mechanics include cleaning through PII removal, deduplication, and noise filtering, followed by normalization, tokenization alignment, and applying model-specific chat templates. Skipping any of these steps introduces compounding errors downstream.
Here is the sequence that works:
- Collect your raw data from all sources and consolidate into a single staging environment.
- Remove PII using regex patterns, named entity recognition, or dedicated tools like Microsoft Presidio. This is non-negotiable.
- Deduplicate at both the exact-match and near-duplicate level. Fuzzy matching catches paraphrased repetitions that exact matching misses.
- Filter noise by removing examples that are too short, too long, malformed, or semantically irrelevant to your task.
- Normalize text: standardize encoding (UTF-8), fix whitespace, unify punctuation, and resolve entity inconsistencies.
- Tokenize and align your examples to your target model’s context window. Truncate or chunk sequences that exceed the limit.
- Structure into your chosen format and apply the model’s chat template.
A well-documented dataset cleansing process is not optional infrastructure. It is the foundation your model’s accuracy is built on. Teams that automate steps 2 through 5 using pipeline scripts save dozens of hours per dataset iteration and catch errors that manual review consistently misses.
Warning: Skipping PII removal is not just a privacy risk. It is a regulatory liability. Models trained on PII can memorize and reproduce sensitive information verbatim, exposing your organization to GDPR, HIPAA, or CCPA violations depending on your jurisdiction.
Pro Tip: Automate your data preprocessing workflow using modular scripts. Each cleaning step should be independently testable and logged. This makes debugging a broken training run dramatically faster because you can isolate exactly which transformation introduced the problem.
Deduplication deserves special emphasis. Duplicate examples do not just waste compute. They skew the model’s learned distribution toward overrepresented patterns, increasing overfitting risk and reducing the model’s ability to generalize to real-world inputs it has not seen before.

Formatting data for fine-tuning: Templates and schema validation
Having ensured data quality, you’re ready to format for your target model and prevent schema mishaps.
Cleaned data still needs to be translated into the exact structural format your model expects. This is where many teams make expensive mistakes. Model-specific templates like Llama’s header tags must be applied precisely, and you can validate your formatting using "get_chat_template` before committing to a full training run. A single malformed example can corrupt an entire batch.
Here is how to approach template application systematically:
- Identify your model’s required template from official documentation or the model card. Do not guess.
- Apply the template programmatically using the tokenizer’s
apply_chat_templatemethod where available. - Validate a sample batch of 50 to 100 examples before processing the full dataset.
- Check token counts per example to confirm nothing exceeds the model’s context window.
- Log schema violations so you can trace and fix upstream data issues rather than patching symptoms.
A reference table for common model templates:
| Model family | Template style | Key tokens |
|---|---|---|
| OpenAI GPT | ChatML | `< |
| Llama 3 | Header-based | `< |
| Mistral | Instruction tags | [INST], [/INST] |
| Falcon | Custom roles | User:, Assistant: |
For a deeper look at how to standardize across these models, the dataset standardization guide covers field-level consistency and schema enforcement in detail. And if you are working across multiple model targets simultaneously, dataset structuring tips can help you build a format-agnostic pipeline that adapts without manual rework.
Pro Tip: Always test your formatted dataset with the actual tokenizer before training. Run tokenizer.apply_chat_template(example, tokenize=True) on a handful of examples and inspect the token IDs. Misaligned special tokens are invisible to the eye but catastrophic to the model.
Schema validation is not a one-time step. Build it into your pipeline as a gate that every new batch must pass before it enters training. Treat it like a unit test for your data.
Avoiding common pitfalls: Outliers, diversity, and leakage
To guarantee robust results, it’s vital to address the practical challenges that can undermine your entire fine-tuning effort.
Template mismatches cause incoherent training signals, while lack of diversity leads to poor generalization, data leakage corrupts evaluation splits, and imbalanced datasets require stratified sampling and augmentation to fix. These are not edge cases. They are the most common reasons fine-tuned models underperform in production.
Benchmark contamination risks overfitting, which is why you should always use held-out evaluation variants and actively monitor train/validation loss divergence. A model that looks great on your test set but fails in production has almost certainly seen its evaluation data during training.
Here are the pitfalls to check for in every batch:
- Template mismatches: Does every example use the correct role tags and delimiters for your target model?
- Low semantic diversity: Are your examples covering the full range of inputs the model will encounter, or clustering around a narrow subset?
- Imbalanced class distribution: For classification tasks, are underrepresented classes getting enough examples to be learned reliably?
- Train/test leakage: Do any examples in your test split appear in your training set, even in paraphrased form?
- Long sequence mishandling: Are examples exceeding the context window being chunked intelligently rather than truncated mid-sentence?
- Outlier contamination: Are there examples with extreme token counts, unusual formatting, or corrupted text that skew the learned distribution?
Pro Tip: Use Self-Instruct or similar synthetic data generation methods to boost semantic diversity when your real-world data is sparse. Generate diverse instruction variations, then validate them against your quality criteria before including them in training. Synthetic data works well when it is validated. It fails when it is treated as a free pass.
For a structured approach to dataset curation tips that addresses diversity and balance systematically, the linked guide covers stratified sampling strategies and augmentation workflows in practical detail.
Stratified sampling is your best tool for imbalanced datasets. It ensures that every class or topic cluster is proportionally represented in both training and evaluation splits, which directly improves generalization to real-world distribution.
Why prioritizing quality over quantity changes everything
Having covered the core tactics, let’s consider what most teams get wrong about dataset scale and how to avoid the trap.
The instinct to collect more data is almost universal among AI teams. More examples feel safer. They feel like insurance. But high-quality 10,000 examples outperform larger noisy sets, and we have seen this play out repeatedly with startups that scaled their datasets before validating their quality baseline.
The pattern is predictable. A team collects 500,000 examples, trains for days, and gets a model that is confidently wrong. They scale up the data thinking more will fix it. It does not. The problem was never volume. It was that 60% of their examples were noisy, inconsistent, or structurally misaligned. Scaling noise just trains a noisier model faster.
Our recommendation is to start with 50 to 1,000 carefully curated, gold-standard examples. Validate them rigorously. Train a small model. Evaluate against held-out data. Only then scale. This approach also forces you to confront a question many teams avoid: does this task actually need fine-tuning? For knowledge retrieval tasks, how much data you need is often less than expected because RAG or structured prompting can achieve comparable results without the overhead of a full training pipeline.
Synthetic data is genuinely useful when it is validated against real-world quality criteria. It is not a shortcut. It is a tool. Use it to fill gaps in coverage, not to replace the discipline of curation.
Scale your fine-tuning success with optimized datasets
If you’re ready to put these strategies into action, here’s how you can partner with experts for faster, more reliable results.
Building training-ready datasets at scale is operationally complex. Schema design, deduplication logic, PII removal, template alignment, and validation pipelines all need to work together without introducing new errors. At DOT Data Labs, we handle exactly this: structured, machine-ready dataset production built for LLM fine-tuning, RAG pipelines, and vertical AI systems.

Whether you need a production dataset structure built from scratch or want expert dataset structuring services applied to your existing data, we produce schema-consistent, training-optimized datasets on demand. Start with our machine-ready dataset guide to see exactly what a production-grade dataset looks like before your next fine-tuning run.
Frequently asked questions
What is the preferred data format for LLM fine-tuning?
For most LLMs, JSONL with chat messages or prompt-completion pairs is the standard starting point, but you must align with your specific model’s schema and chat template requirements.
How many samples do I need for fine-tuning?
Start with 50 to 1,000 high-quality examples and validate results before scaling, since expanding a noisy dataset only amplifies overfitting risk rather than improving performance.
Why is PII removal critical for training-ready data?
PII removal prevents models from memorizing and reproducing sensitive information, protecting your organization from regulatory violations under GDPR, HIPAA, and CCPA while keeping your training data clean.
How do I check for data leakage in my splits?
Always use held-out evaluation sets that are completely separate from training data, and monitor training versus validation loss divergence throughout the run to catch leakage early.
Recommended
- Dot Data Labs — High-Quality Data for Training AI Models — Providing datasets for AI training
- Machine-Ready Dataset Guide: Build Optimized AI Training Sets – Dot Data Labs – High-Quality Data for Training AI Models
- Master data preprocessing workflow: boost AI accuracy 2026
- Top AI data structuring methods for superior model training