
What Is Unstructured Data? A 2026 Guide for Data Teams

TL;DR:
- Unstructured data comprises information without a predefined schema, including images, audio, and social media posts. It accounts for up to 90% of enterprise data growth and requires specialized pipelines and AI techniques for analysis. Proper management and preprocessing of raw files are essential for effective AI, machine learning, and business intelligence applications.
Unstructured data is defined as any information that lacks a predefined schema or organizational model, making it incompatible with traditional relational databases and standard query tools. Text documents, images, audio recordings, video files, and social media posts all qualify. According to Wikipedia, unstructured data is often text-heavy but also includes irregular dates, numbers, and facts that conventional software struggles to process. IBM estimates that 80% to 90% of enterprise data growth falls into this category. That figure alone explains why managing it has become a top priority for every serious data team in 2026.
What is unstructured data vs. structured data?
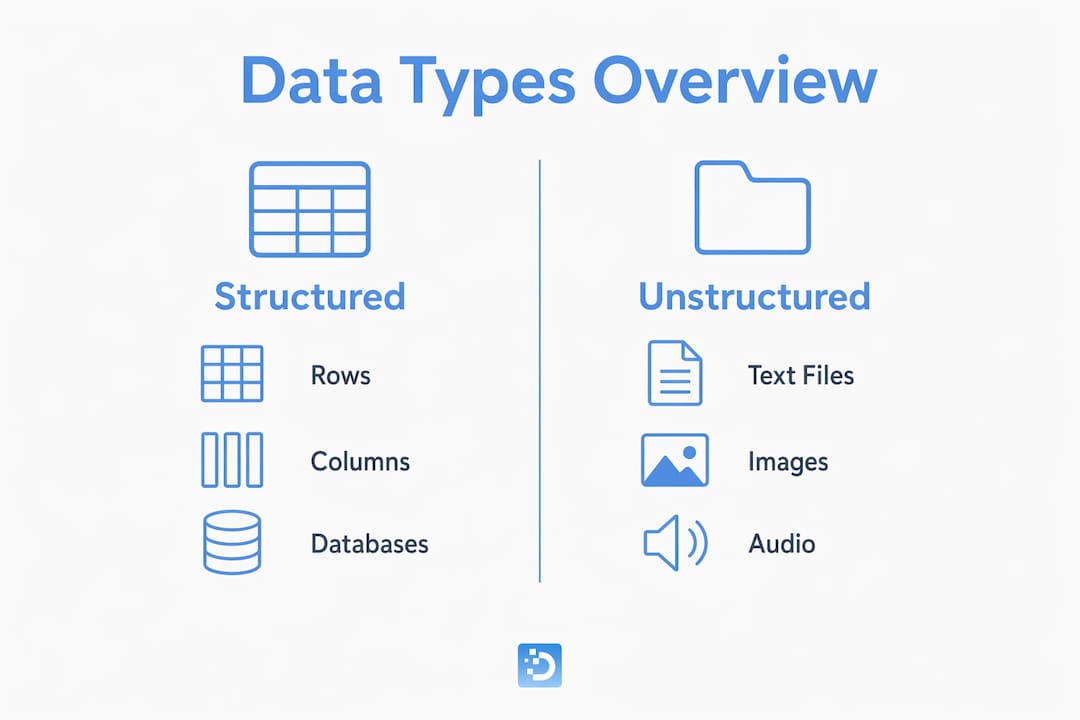
Structured data lives in rows and columns inside relational databases like PostgreSQL or MySQL. Every field has a defined type, every record follows the same schema, and SQL queries return results in milliseconds. Unstructured data has none of that. As TechTarget defines it, unstructured data is textual or nontextual, human or machine generated, and exists without a predetermined data model.

The storage difference is just as significant as the format difference. Structured data sits in relational databases optimized for transaction processing. Unstructured data lives in native file formats inside data lakes, object stores like Amazon S3 or Azure Blob Storage, or distributed file systems like Hadoop HDFS. You cannot run a SQL JOIN across a folder of JPEG images.
The analysis tools diverge sharply too. Structured data teams reach for SQL, Tableau, or Power BI. Unstructured data requires natural language processing (NLP), computer vision, speech recognition models, or embedding-based retrieval systems. The preprocessing burden alone separates the two workflows by an order of magnitude.
Pro Tip: Before choosing a storage architecture, decide whether your primary use case is archival retrieval or real-time model inference. That single decision determines whether a data lake or a vector database is the right home for your unstructured assets.
| Dimension | Structured data | Unstructured data |
|---|---|---|
| Schema | Predefined, rigid | None or flexible |
| Storage | Relational databases | Data lakes, object stores |
| Query method | SQL | NLP, ML, embeddings |
| Primary use | Transaction processing | BI, AI model training |
| Examples | Sales records, CRM logs | Emails, video, audio |
Common examples and types of unstructured data
Unstructured data splits cleanly into two categories: human-generated and machine-generated. Human-generated examples include emails, Word documents, PDF contracts, social media posts, customer support transcripts, and medical notes written by clinicians. Machine-generated examples include server logs, IoT sensor streams, satellite imagery, and surveillance video feeds.
Industry context shapes which types matter most:
- Healthcare: Clinical notes, radiology images (DICOM files), pathology slides, and patient intake forms. These are among the most annotation-intensive datasets in any sector.
- Automotive: LiDAR point clouds, dashcam video, and GPS telemetry from test fleets. A single autonomous vehicle generates roughly 4 terabytes of raw data per day.
- Finance: Earnings call transcripts, SEC filings, analyst reports, and customer complaint emails. Sentiment extracted from these sources feeds credit risk and trading models.
- Retail and e-commerce: Product reviews, customer chat logs, and user-uploaded images for visual search systems.
Databricks notes that the sheer volume and variety of unstructured data demands advanced analytics methods including NLP, computer vision, and machine learning. That demand is not theoretical. It shows up in every data pipeline budget conversation happening right now.
How to analyze unstructured data: challenges and techniques
The core challenge of unstructured data processing is the absence of schema. You cannot filter a folder of audio files by “customer sentiment” without first transcribing the audio, running a sentiment model, and storing the output somewhere queryable. Every analysis step requires a preprocessing step before it.
Historically, that preprocessing was entirely manual. Annotators labeled images by hand, linguists tagged named entities in text corpora, and data engineers wrote brittle parsers for each new file format. MIT Sloan reports that 87% of IT leaders prioritized managing unstructured data growth in 2022. That priority has only intensified since then, as model training datasets have grown larger and more diverse.
Modern techniques have changed the economics significantly:
- NLP pipelines convert raw text into tokenized, embedded representations that models can consume directly. Tools like spaCy, Hugging Face Transformers, and OpenAI embeddings handle most standard text workflows.
- Computer vision models extract objects, scenes, and attributes from images and video without manual labeling at inference time. Pre-trained models from PyTorch and TensorFlow dramatically reduce cold-start costs.
- Speech-to-text systems like Whisper convert audio to structured transcripts, which then feed downstream NLP pipelines.
- Embedding generation converts any content type into dense vector representations stored in databases like Pinecone or Weaviate, enabling semantic search and retrieval-augmented generation.
“Deep learning’s impact on unstructured data use is one of the most significant analytics breakthroughs.” — MIT Sloan professor Rama Ramakrishnan
MongoDB explains that real-world unstructured data pipelines create derived searchable artifacts, separating archival native storage from the analytical layer. The raw file stays in cold storage. The embedding or extracted metadata lives in a fast, queryable index. That architectural separation is the standard pattern in production AI systems today.
Pro Tip: Never discard raw unstructured files after processing. Store originals in object storage and maintain derived representations separately. Model architectures change, and you will want to reprocess the same source data against a better model six months from now.
How unstructured data powers AI, machine learning, and business intelligence
Unstructured data is the primary fuel for modern AI model training. Computer vision models require millions of labeled images. Large language models train on trillions of tokens of text. Speech recognition systems need thousands of hours of transcribed audio. None of those training sets are structured in the relational sense.
The practical applications span every major industry vertical:
- Sentiment analysis on customer reviews and support tickets gives product teams signal that structured NPS scores miss entirely.
- Medical imaging AI reads radiology scans faster and with comparable accuracy to radiologists, but only when trained on high-quality annotated DICOM datasets.
- Document intelligence extracts structured fields from unstructured PDFs, contracts, and invoices, feeding downstream structured workflows.
- Multimodal AI combines text, image, and audio inputs in a single model, which requires training data that spans all three formats simultaneously.
MIT Sloan’s research confirms that deep learning allows unstructured and structured data to be leveraged together, marking a major breakthrough in analytics capability. Platforms like Databricks Delta Lake, Snowflake, and Apache Iceberg now support lakehouse architectures that store unstructured files alongside structured tables in a single governed environment. That convergence is what makes unified AI and BI workflows possible at scale. For teams building AI models, understanding why AI needs structured data alongside unstructured inputs is the foundation of any serious training data strategy.
Key takeaways
Unstructured data requires purpose-built pipelines that separate raw archival storage from derived analytical representations, and that separation is the single most important architectural decision any data team makes.
| Point | Details |
|---|---|
| Definition matters | Unstructured data lacks a predefined schema, making it incompatible with SQL and relational databases. |
| Scale is the reality | Unstructured data accounts for 80% to 90% of enterprise data growth, demanding dedicated management strategies. |
| Preprocessing is non-negotiable | Raw files must be converted to embeddings, transcripts, or metadata before any model can consume them. |
| Architecture separates storage and analysis | Native files belong in object storage; derived representations belong in queryable indexes or vector databases. |
| Deep learning changed the economics | Modern NLP and computer vision models reduce the manual annotation burden that made unstructured data prohibitively expensive to use. |
Why most teams underestimate the preprocessing problem
After working with data teams across healthcare, automotive, and finance, the pattern I see most often is this: teams underestimate preprocessing by a factor of three. They budget for model training and forget that getting raw unstructured files into a model-ready format is where most of the time and cost actually lives.
The hidden work in AI data quality is rarely glamorous. It is deduplication, format normalization, metadata extraction, and quality validation. Teams that skip it pay later in model performance. The good news is that data preprocessing workflows have matured significantly. The bad news is that most internal teams still treat preprocessing as an afterthought rather than a first-class engineering problem.
My honest recommendation: treat your unstructured data pipeline as a product, not a script. Version your raw files. Track your derived representations. Document your annotation schemas. The teams that do this ship better models faster, and they can reprocess historical data when a better model architecture arrives. The teams that do not end up rebuilding from scratch every 18 months.
— Oleg
How DOT Data Labs handles unstructured data at scale

DOT Data Labs manages the full pipeline from raw unstructured files to labeled, validated, model-ready datasets. Whether your team needs annotated medical imaging data, transcribed and aligned audio, or large-scale web text collections, DOT Data Labs handles sourcing, cleaning, annotation, and delivery in formats your training infrastructure can consume directly.
Recent projects include 50,000 hours of talking-head video with aligned subtitles and a 32 million science Q&A dataset delivered in under 30 days. DOT Data Labs offers off-the-shelf datasets for immediate use, one-off custom builds scoped to your exact specifications, and ongoing data pipelines for teams that need continuous training data. Explore custom AI training datasets or review specialized healthcare AI training data for domain-specific needs.
FAQ
What is unstructured data in simple terms?
Unstructured data is any information that does not fit neatly into rows and columns, such as emails, images, audio files, and social media posts. It lacks a predefined schema, which makes it incompatible with traditional relational databases and SQL queries.
What are the most common examples of unstructured data?
The most common examples include text documents, PDFs, emails, social media content, images, video recordings, audio files, and machine-generated logs. In enterprise settings, customer support transcripts and medical records are among the highest-volume sources.
How is unstructured data different from structured data?
Structured data follows a fixed schema stored in relational databases and is queried with SQL. Unstructured data has no fixed format, lives in data lakes or object stores, and requires NLP, computer vision, or embedding techniques to analyze.
Why is unstructured data important for AI?
Unstructured data is the primary training material for computer vision, NLP, and speech recognition models. Without large volumes of labeled unstructured data, modern AI systems cannot reach production-grade accuracy.
What tools are used to process unstructured data?
Common tools include spaCy and Hugging Face Transformers for text, PyTorch and TensorFlow for image and video, OpenAI Whisper for audio transcription, and Pinecone or Weaviate for storing and querying vector embeddings at scale.