
Streamline structured data extraction for AI training

TL;DR:
- Efficient extraction of structured data from unorganized documents is critical for AI model performance.
- A multi-stage pipeline with validation, schema enforcement, and versioning ensures high-quality, reliable datasets.
- Fine-tuning domain-specific models and iterative validation reduce errors and improve extraction accuracy.
Your AI model’s accuracy and deployment timeline hinge on one thing more than almost anything else: how efficiently and reliably you can extract structured datasets from massive, unorganized document collections. If your input data is messy, inconsistent, or poorly formatted, even the most sophisticated model architecture will underperform. Yet most teams rush through extraction, treating it as a preprocessing footnote rather than a critical engineering discipline. This guide breaks down the complete process, from pipeline design to validation, covering the tools, best practices, and pitfalls that separate production-grade extraction workflows from ones that quietly sabotage your training runs.
Key Takeaways
| Point | Details |
|---|---|
| Pipeline clarity | Structured extraction workflows with well-defined stages reduce errors and accelerate AI model training. |
| Tool and framework fit | Choosing the right mix of schema enforcement, fine-tuning, and benchmarking tools maximizes extraction reliability. |
| Validation is critical | Data validation and strict schema enforcement are essential for model-ready outputs and successful AI deployments. |
| Iterate for robustness | Tweaking your pipeline for edge cases and iterating based on regular benchmarks lead to long-term workflow success. |
Understand the end-to-end structured data extraction pipeline
Now that we’ve set the stage for why structured data extraction is essential, let’s break down the life cycle of a high-velocity data extraction workflow.
A structured data extraction pipeline is not a single step. It’s a sequence of interdependent stages, each one feeding the next, where errors compound quickly if left unchecked. The data preprocessing workflow alone can account for 60 to 80 percent of total project time in most ML pipelines. Understanding each stage in sequence helps you design for reliability from the start.
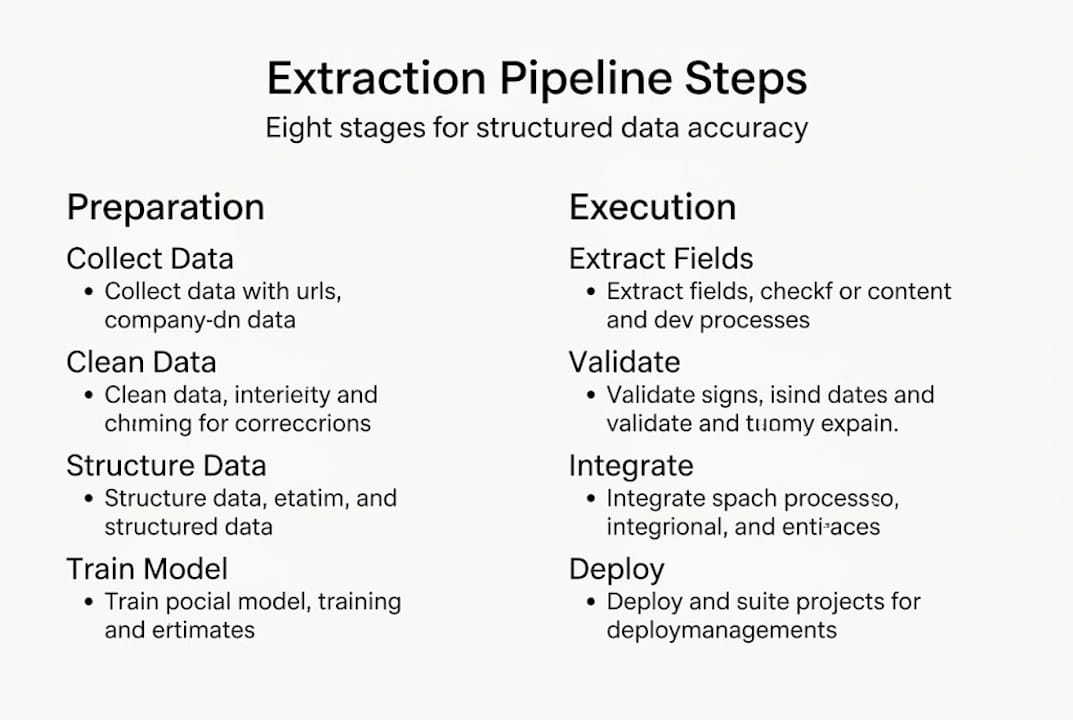
The AI data structuring methods that work at scale share a common architecture. According to AI data extraction research, the pipeline stages involve document ingestion, preprocessing, classification, extraction via NLP or computer vision, contextual understanding, validation, and export to structured formats like JSON or CSV. Each stage is a quality gate, not just a processing step.
Here’s a breakdown of how each stage operates in practice:
| Pipeline stage | Function | Typical tools or methods |
|---|---|---|
| Collection | Gather documents from APIs, databases, scrapers | Web crawlers, API connectors, S3 buckets |
| Cleaning | Remove noise, fix encoding, normalize whitespace | Python regex, pandas, custom parsers |
| Structuring | Apply schema and field definitions | JSON Schema, Pydantic, dataclasses |
| Training | Train or fine-tune extraction models | SLMs, QLoRA, Hugging Face Transformers |
| Extraction | Pull target fields from documents | LLMs with structured output, NLP/CV models |
| Contextual understanding | Resolve ambiguity, link entities | Coreference resolution, entity linkers |
| Post-processing | Normalize, deduplicate, fill nulls | Custom logic, fuzzy matching |
| Integration | Export to training-ready formats | JSON, CSV, Parquet, API endpoints |
A practical walk-through scenario helps make this concrete. Suppose you’re building a vertical AI system for commercial real estate:
- You collect lease agreements in PDF format from an S3 bucket.
- You preprocess them by extracting raw text with a PDF parser and stripping headers and footers.
- You classify each document by lease type using a lightweight classifier.
- You run structured extraction to pull fields like tenant name, square footage, and lease term.
- You apply contextual understanding to resolve references like “the property” back to a specific address.
- You validate every extracted record against your schema, flagging nulls and outliers.
- You post-process to deduplicate entries from the same tenant across multiple documents.
- You export the final dataset as newline-delimited JSON, ready for fine-tuning.
Consistency and traceability are not optional. Every extraction decision must be logged for model auditability. If your pipeline produces different results on the same input across runs, your training data is compromised before the first epoch.
Refer to our machine-ready dataset guide for format specifications that downstream models actually expect.
Tools, frameworks, and requirements for modern extraction workflows
With each stage clarified, the next decision is tool selection and requirements, factors that shape the entire workflow.
Not every team needs to build a custom extraction model. In 2026, the landscape offers a spectrum of solutions, from zero-fine-tune pipelines to highly specialized domain models. Choosing the wrong approach burns compute budget and engineering time without improving output quality.
Essential requirements before you select a tool:
- Scalable compute that can process thousands of documents in batch mode
- Support for your document formats, including PDFs, HTML pages, DOCX files, and images
- Native schema enforcement to prevent downstream compatibility failures
- Logging and lineage tracking for auditable extraction outputs
- Error handling for malformed, truncated, or ambiguous inputs
Here’s a direct comparison of the primary tool categories in use today:
| Tool or approach | Best for | Trade-offs |
|---|---|---|
| OpenAI with JSON mode | Fast no-fine-tune pipelines, general documents | Cost at scale, latency, schema drift risk |
| LangExtract | Chained extraction with prompt orchestration | Requires prompt engineering expertise |
| Off-the-shelf SLMs | Low-latency, on-premise needs | Lower accuracy on complex schemas |
| Fine-tuned SLMs | Domain-specific extraction at scale | Upfront training cost, data needed |
| Databricks AI_QUERY | Batch processing on structured data lakes | Requires Databricks environment |
According to benchmark research from extract-bench, teams should prioritize JSON schema enforcement and structured outputs for quick no-fine-tune pipelines, fine-tune SLMs for domain-specific gains, and use benchmarks like extract-bench for systematic evaluation. Edge cases should be handled with multi-step approaches, chunking strategies, or hybrid methods.
When deciding between no-fine-tune and custom fine-tuning, the decision criteria are straightforward. If your document types are relatively uniform and your schema has fewer than 15 fields, a structured output LLM with strict JSON mode will often suffice. If you’re dealing with domain-specific terminology, inconsistent layouts, or extraction accuracy requirements above 95 percent, fine-tuning a small language model on labeled examples will consistently outperform.
For AI data structuring comparison across these approaches, the accuracy gap between general and fine-tuned models widens significantly on long-tail document types.
Pro Tip: Lock your JSON schema to exact field names, types, and required flags before running any extraction. Schema drift between pipeline iterations is one of the leading causes of silent data corruption in AI training sets. Use Pydantic or JSON Schema validators to enforce this at the output layer, not after the fact. For rapid iteration, maintain a versioned schema registry so you can roll back if a schema change breaks downstream compatibility. See our proven data structuring steps for schema versioning patterns that work in production.
Step-by-step structured data extraction: Process and best practices
Selecting the right tools is half the battle. Executing the process methodically, and avoiding common mistakes, makes all the difference.
The 8-step pipeline covering collection, cleaning, structuring, training, extraction, contextual understanding, post-processing, and integration forms the backbone of any reliable extraction workflow. Here’s how to execute each step with precision:
-
Ingest documents. Pull from your source system using batch-safe connectors. Always record file hashes at ingestion time so you can detect changes or duplicates downstream. Never overwrite source files.
-
Preprocess raw inputs. Strip metadata noise, normalize encoding to UTF-8, and segment long documents into logical chunks of 512 to 1024 tokens. This prevents extraction models from losing context on page boundaries.
-
Classify document types. Apply a lightweight classifier to sort documents by type before extraction. Sending a legal contract to an extraction prompt designed for invoices will produce garbage output.
-
Extract using NLP or CV. Run your extraction model against each classified document segment. Use structured output enforcement at this layer. For image-based documents, apply OCR first, then feed the text output to your extraction model.
-
Apply contextual understanding. Resolve entity references, handle coreference, and link extracted values back to their canonical identifiers. This is where entity resolution earns its keep.
-
Validate every record. Check field counts, verify data types, measure null rates, and confirm value ranges. Records that fail validation should be routed to a review queue, not silently dropped.
-
Post-process and normalize. Standardize date formats, normalize company names using fuzzy matching, and deduplicate across document sources. Lean on dataset cleansing best practices for this step.
-
Export to integration formats. Output as newline-delimited JSON, CSV, or Parquet depending on your downstream pipeline. Attach schema version metadata to every output file.
Common mistakes and how to avoid them:
- Skipping document classification: Sending mixed document types to a single extraction prompt inflates error rates. Always classify first.
- Ignoring null rates until the end: A null rate above 5 percent on a critical field often signals a structural parsing failure, not a data absence. Catch it early by reviewing data preprocessing steps to identify root causes.
- Using one extraction prompt for all document lengths: Long documents exceed context windows and produce truncated or hallucinated fields. Chunk them.
- Skipping schema versioning: Updating your schema mid-pipeline without versioning corrupts historical comparisons.
- Treating validation as optional: Unvalidated extraction outputs feed bad data directly into training, compounding errors silently across epochs.
Pro Tip: For long-form documents like research papers, legal contracts, or financial reports, implement a two-pass chunking strategy. In the first pass, extract section-level structure (headings, paragraphs, tables). In the second pass, run field-level extraction against each section. This reduces hallucinations, improves precision, and makes it far easier to trace which part of a document produced each extracted value.
How to ensure high-quality outputs: Validation, schema, and integration
You’ve extracted your data. Now, the focus turns to quality control and making the outputs work for your training pipelines.

Extraction without rigorous validation is just structured noise. High-quality AI training datasets require not just accurate extraction, but consistent, schema-compliant, and integration-ready outputs. Here’s how to build that reliability into your workflow.
Schema enforcement for JSON and CSV outputs is the single most impactful quality lever you can pull. As extract-bench research confirms, prioritizing JSON schema enforcement and structured outputs is essential for reliable no-fine-tune pipelines. This means defining field types, required flags, and allowable value ranges before extraction runs, then validating every output record against that schema automatically.
Your output validation checklist should include:
- Field count: Every record should have the exact number of fields your schema defines, no more, no fewer.
- Type conformance: Dates as ISO 8601 strings, numbers as floats or integers, booleans as true or false, never as strings.
- Allowable values: Categorical fields should only contain values from a predefined list. Anything outside that list routes to review.
- Null rates by field: Track null rates at the field level across your dataset. A sudden spike often indicates a document format change or extraction model degradation.
- Structure conformity: Nested JSON objects must conform to the expected hierarchy. Flat structures are simpler to validate but less expressive.
- Duplicate records: Identical or near-identical records should be detected and flagged before entering training pipelines.
For domain-specific extraction tasks, fine-tuning SLMs or using QLoRA on domain data significantly improves accuracy compared to general-purpose LLMs. A fine-tuned SLM trained on 5,000 labeled examples from your specific document type will typically outperform a much larger general model on both precision and recall for your target fields.
Use our dataset validation strategies guide to implement automated validation gates as part of your CI pipeline for dataset production.
“Benchmarks like extract-bench reveal gaps in pipeline reliability that internal spot-checks consistently miss.” Systematic evaluation against held-out document sets is the only way to measure true extraction performance before it reaches training.
Review the structured dataset impact data to understand how validation quality directly affects downstream model performance metrics.
What most guides miss about real-world structured data extraction
Most extraction guides describe clean, linear pipelines. Real-world extraction is messier, and that gap matters more than most teams realize.
The biggest blind spot we see consistently is underestimating schema drift. Teams define a schema early, run it through hundreds of documents, then quietly update a field definition mid-project without versioning. Three weeks later, they can’t explain why model accuracy degraded. Schema drift between iterations is invisible unless you build version control into your schema management from day one.
The second pattern that separates high-performing teams is iterative validation. Rather than validating once at the end, they validate after every pipeline stage. This means problems surface at classification, not at integration. It’s cheaper to catch a parsing failure at preprocessing than to retrain a model on corrupted data.
Teams that commit to routinely benchmarking against held-out document sets, using extract-bench or in-house evaluation suites, see significantly fewer post-deployment surprises. It’s not glamorous work. But systematic evaluation before training, not after deployment, is what keeps pipelines reliable at scale.
Consult our AI data quality checklist to build iterative validation into your workflow from the start.
Finally: immediate JSON schema enforcement is rarely enough for long-tail document scenarios. Hybrid approaches that combine structured output LLMs with rule-based post-processors consistently outperform single-method pipelines when document diversity is high.
Accelerate structured data extraction with Dot Data Labs
If you want rigorous, production-ready data pipelines without the heavy lift, here’s how Dot Data Labs can help.
Building and maintaining a structured data extraction pipeline at scale requires sustained engineering investment in schema design, validation logic, and format standardization. Dot Data Labs handles this entire layer for AI startups, ML engineers, and research teams who need machine-ready datasets without building the infrastructure from scratch.

We produce large-scale, schema-consistent datasets formatted for LLM fine-tuning, RAG pipelines, and classification models. Our extraction workflows include automated validation, entity resolution, and deduplication built in. Explore our structured datasets guide for format specifications and pipeline examples, or review our ML datasets step-by-step guide to understand how custom dataset production works end to end. If you’re ready to discuss your data requirements, reach out for a consultation.
Frequently asked questions
What is structured data extraction in AI?
Structured data extraction is the automated process of converting unstructured or semi-structured documents into organized, machine-readable formats. Outputs are typically exported as JSON or CSV for use in AI model training, fine-tuning, and analysis pipelines.
What are the most common steps in a structured data extraction process?
The core steps follow an 8-step pipeline covering collection, cleaning, structuring, optional training, extraction, contextual understanding, post-processing, and integration into downstream AI systems.
Should I fine-tune a small language model (SLM) for data extraction?
Yes, in most domain-specific scenarios. Fine-tuning SLMs or using QLoRA on domain data significantly improves extraction accuracy compared to deploying general-purpose LLMs against specialized document types.
How do you handle edge cases in structured data extraction?
Use multi-step or hybrid extraction methods combined with chunking for long documents, and benchmark regularly with extract-bench or an in-house evaluation suite to catch reliability gaps before they reach training.
What formats should the outputs of extraction pipelines target?
Outputs should target widely compatible formats. Structured formats like JSON or CSV ensure seamless compatibility with ML frameworks, fine-tuning pipelines, and downstream retrieval or classification systems.