
What Is Data Structuring? A Practical 2026 Guide

TL;DR:
- Data structuring is essential for organizing raw data into accessible, analyzable formats, preventing AI and analytics issues. Effective schema design, iteration, and stakeholder alignment improve data quality, speed, and governance, supporting scalable AI workflows. Treat schemas like code, continuously evolving with changing business needs to maintain data integrity and usefulness.
Most people assume data structuring is a developer concern. Something that happens in the background, handled by engineers, invisible to anyone who actually uses the data. That assumption is exactly what leads to broken AI models, inconsistent analytics, and months of cleanup work no one budgeted for. Understanding what is data structuring, at a decision-maker level, is the first step toward building data pipelines that actually perform. This guide covers the definition, methods, benefits, and practical steps your team needs.
Key Takeaways
| Point | Details |
|---|---|
| Data structuring is foundational | It organizes raw data into formats machines and analysts can reliably access and analyze. |
| Structured vs. unstructured data | Structured data follows fixed schemas; unstructured data requires AI or NLP processing to interpret. |
| Schema design is ongoing | Treat schemas like application code, with version control and iteration as business needs evolve. |
| Poor structure breaks AI | Inconsistent data formats create silos, unreliable model outputs, and costly reconciliation work. |
| Business and technical teams must align | Effective data structuring requires collaboration between stakeholders who understand the use case and the system. |
What is data structuring and why it matters
Data structuring is the intentional process of organizing data into formats such as tables, trees, and graphs so that computers can access, search, and analyze it efficiently. It is not just about storing data. It is about defining the rules that govern how data relates to other data and what operations can be performed on it.
The simplest way to understand the data structuring definition is through contrast. Structured data follows a fixed schema, organized in rows and columns, like a relational database table tracking customer transactions. Unstructured data has no predefined format. Think of raw audio recordings, free-form support tickets, or social media posts. Both have value, but unstructured data requires additional AI or NLP processing before a model can learn from it reliably.
The core goals of data structuring are:
- Efficiency: Machines retrieve and process structured data faster than unstructured formats
- Accessibility: Analysts and models can query structured data without guessing at format or meaning
- Analysis support: Consistent schema design makes aggregation, filtering, and reporting predictable
- AI readiness: Structured training data reduces preprocessing time and produces more reliable model outputs
For AI teams specifically, the importance of data structuring comes down to one thing. Garbage in, garbage out. A model trained on inconsistently structured data will produce inconsistent outputs. That is not a model problem. It is a data problem.
Common data structuring methods and models

Not all data structuring looks the same. The method you choose depends on your use case, your access patterns, and how your downstream consumers, whether analysts or ML models, will query the data.
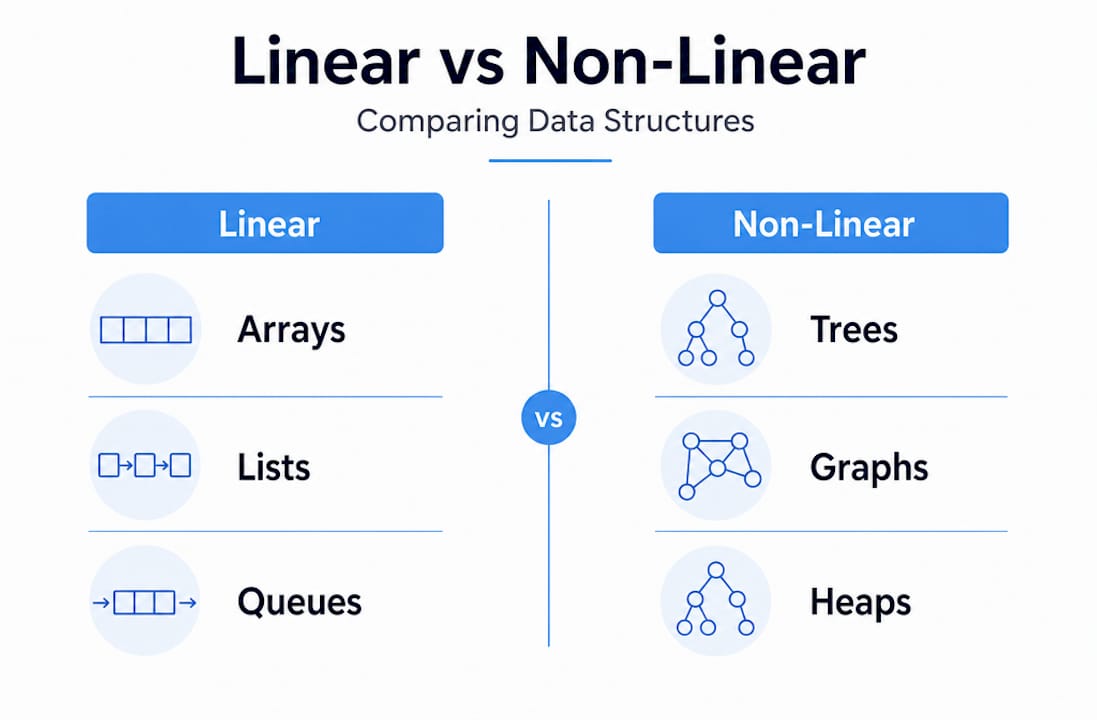
Linear vs. non-linear structures
Linear structures organize data sequentially. Arrays store elements at contiguous memory locations. Linked lists connect nodes through pointers. Queues and stacks control the order of data access. These are foundational to how most transactional systems and APIs handle data in motion.
Non-linear structures represent relationships more flexibly. Trees model hierarchies, like product categories or organizational charts. Graphs represent networks where any node can connect to any other, which is why knowledge graphs are increasingly common in modern AI systems.
Data modeling types
| Model type | What it defines | Best used for |
|---|---|---|
| Conceptual | High-level entities and relationships | Aligning stakeholders on scope |
| Logical | Attributes, data types, constraints | Detailed design without DB specifics |
| Physical | Actual tables, indexes, storage | Implementation and performance tuning |
Schemas for analytics and AI
When it comes to data warehousing and analytics, two schema designs dominate. Star schema uses a central fact table linked to denormalized dimension tables. It is preferred for performance and analyst ease. Snowflake schema normalizes those dimensions further, reducing redundancy but adding join complexity. For most AI training workflows, star schema wins on speed and simplicity.
A hybrid approach works well in practice. Keep normalized raw data for integrity and auditability. Build denormalized reporting layers, like star schemas, on top for query performance. This balances flexibility with the speed analysts and model pipelines need.
Pro Tip: When evaluating which schema to use, map your most frequent query patterns first. The best schema is the one your actual workloads can run efficiently, not the one that looks cleanest on a whiteboard.
Key benefits of data structuring in AI and business
The benefits of data structuring are most visible when they are absent. Teams that skip deliberate schema design spend more time cleaning data than building features. Here is what well-structured data actually delivers.
-
Faster data preparation. Consistent schemas and naming conventions cut the time spent cleaning and reconciling data. Your team focuses on building models, not untangling field mismatches between source systems.
-
More accurate AI training. When training data follows a predictable structure, models learn from signal rather than noise. Schema inconsistency is one of the most common causes of underperforming models that look fine in testing but fail in production.
-
Fewer data silos. Poor data structure creates isolated datasets that teams cannot easily combine. Governed data models with shared definitions make cross-team analysis possible without custom ETL work every time.
-
Better governance and compliance. Structured data is auditable. You know where fields come from, what they mean, and who has access. That matters when you are dealing with personal data or regulated industries.
-
Scalability. A schema designed with access patterns in mind scales with your data volume. One built without that thinking becomes a bottleneck the moment you move from prototype to production.
“The primary goal of data structuring is to convert data into an asset, reducing time wasted on cleaning and reconciling so teams can focus on insights and outcomes.” (What is data organization?)
Practical steps for structuring data effectively
Knowing how to structure data is one thing. Actually doing it well inside a real organization with competing priorities is another. These steps reflect what works in practice.
-
Start with use cases, not schemas. Grounding schema design in real access patterns prevents elegant but impractical designs. Ask what queries your models and analysts will run most often. Then design for those, not for theoretical completeness.
-
Treat your schema like application code. Version control schema changes the same way you version software. Untracked schema drift is one of the fastest ways to break a downstream model without knowing why.
-
Iterate and expect change. Data modeling is iterative by nature. Business needs evolve, new data sources come online, and use cases shift. A schema that cannot adapt becomes a liability faster than most teams expect.
-
Normalize for integrity, denormalize for performance. Keep your raw data layer clean and normalized. Build flattened, denormalized views for the layers that analysts and models actually touch. This separation protects data quality while keeping query speeds acceptable.
-
Include business stakeholders early. Technical teams build the structure. Business teams define what the data needs to mean. Skipping that alignment produces schemas that are technically correct but practically useless.
Pro Tip: Document not just what each field contains, but why it was designed that way. Schema documentation that explains intent, not just format, survives team turnover far better than field definitions alone.
You can also explore AI dataset structuring techniques that apply these principles specifically to machine learning workflows.
My take on where data structuring really breaks down
I have seen a lot of teams treat data structuring as a one-time deliverable. Someone designs a schema at the start of a project, it gets signed off, and then it slowly becomes outdated while the actual data grows in directions nobody planned for.
In my experience, the real failure is not bad schema design. It is the assumption that schema design ever ends. The organizations that handle this well treat their data models the way their engineering teams treat their codebase, with pull requests, reviews, and version history. The ones that struggle treat schemas as artifacts, things you produce once and file away.
I have also found that the hardest part of good data structuring is not technical at all. It is getting a product manager, a data engineer, and an ML researcher in the same room to agree on what a “user” or a “session” or an “event” actually means before anyone writes a line of schema definition. That conversation, uncomfortable as it can be, is where real data quality gets built or destroyed.
If your AI outputs are inconsistent and you cannot figure out why, I would start there. Not with the model. With the definitions.
— Oleg
How Dotdatalabs helps you get data structure right

Dotdatalabs handles the full data supply chain, from sourcing and collection through cleaning, labeling, and structured delivery in model-ready formats. If your team is spending more time wrangling data than training models, that is exactly the problem Dotdatalabs was built to solve. Whether you need a one-off custom dataset built to your schema specifications or an ongoing pipeline delivering structured, validated training data at scale, the team at Dotdatalabs can scope and deliver it without you managing multiple vendors. Explore data sourcing and collection services to see what full-stack delivery actually looks like in practice.
FAQ
What is the data structuring definition?
Data structuring is the process of organizing data into defined formats, like tables, trees, or graphs, so it can be efficiently accessed, queried, and analyzed by both humans and machines.
Why is data structuring important for AI?
Poor data structure creates inconsistencies that degrade model training quality and produce unreliable outputs. Well-structured data reduces preprocessing time and improves the accuracy of AI systems from the start.
What are common data structuring examples?
Common examples include relational database tables with defined schemas, JSON objects with typed fields, star schemas in data warehouses, and labeled feature vectors in machine learning datasets.
How do you choose between star and snowflake schema?
Star schema is preferred when query performance and analyst usability matter most. Snowflake schema suits situations where storage efficiency and reducing data redundancy are higher priorities than join simplicity.
How often should data schemas be updated?
Schemas should be treated as living documents and updated whenever business needs, data sources, or access patterns change. Version control for schema changes is the most reliable way to manage this without breaking downstream systems.