
What Is Annotation in AI? A Practitioner’s Guide

TL;DR:
- Annotation in AI involves labeling raw data to enable effective machine learning training. It is a critical process that transforms unstructured inputs into structured, meaningful examples, directly impacting model accuracy and performance.
Annotation in AI is the process of labeling raw data so machine learning models can learn from it. Without labeled examples, supervised learning pipelines have no signal to train on. A raw image of a pedestrian means nothing to a model until a human marks it with a bounding box and the label “person.” That act of structured labeling, applied consistently across thousands or millions of examples, is what transforms unstructured data into a usable training set. Tools like CVAT and platforms built around ground truth validation have made this process more systematic, but the core discipline remains the same: encode human judgment into a format a model can consume.
What is annotation in AI and why does it matter?
Annotation in AI involves detailed markup beyond simple labeling. It includes drawing bounding boxes, transcribing speech, adding semantic metadata, and marking feature points across text, images, audio, and video. Each of these actions gives a model structured, meaningful examples to learn patterns from.

The importance of annotation in AI becomes clear when you look at where models fail. A model trained on inconsistently labeled data learns inconsistent behavior. Poor annotation quality leads directly to inaccurate models. That finding from data-centric AI research is not a warning about edge cases. It describes the default outcome when annotation is treated as a low-priority task.
Annotation sits at the foundation of supervised learning, which still powers the majority of production AI systems in use today. Every classification model, object detector, speech recognizer, and named entity extractor depends on labeled training data. The quality of that data determines the ceiling of model performance, regardless of how much you tune the architecture.
What are the main types of AI annotation?
Common annotation modalities include classification tags, bounding boxes, semantic segmentation, and keypoints. Each produces a different supervision signal and suits a different task.
| Annotation Type | Description | Typical Use Case |
|---|---|---|
| Classification tag | Single label assigned to a whole image or text sample | Sentiment analysis, image categorization |
| Bounding box | Rectangle drawn around an object in an image | Object detection, autonomous vehicles |
| Semantic segmentation | Pixel-level labeling of every region in an image | Medical imaging, scene understanding |
| Keypoints | Specific feature points marked on a subject | Pose estimation, facial recognition |
| Transcription | Speech or audio converted to text with speaker labels | Voice assistants, meeting transcription |
| Named entity tagging | Text spans labeled by category (person, location, org) | NLP, information extraction |
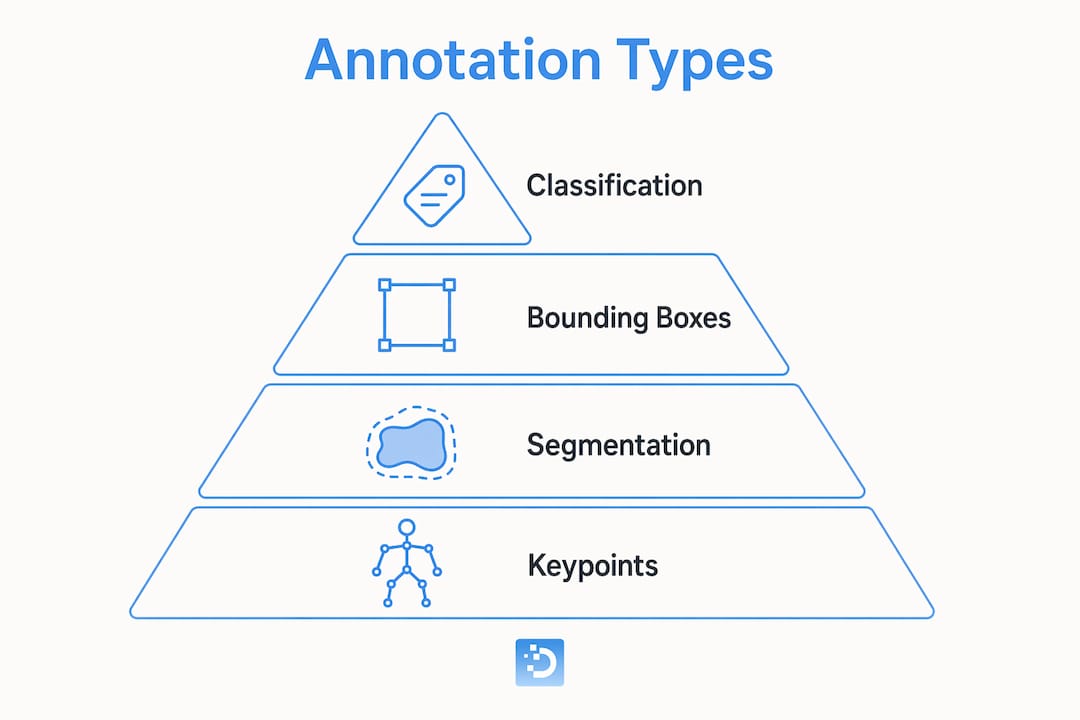
The choice of annotation type is not aesthetic. It directly determines what a model can learn. Bounding boxes tell a model where an object is. Semantic segmentation tells it exactly which pixels belong to that object. Keypoints tell it how a body or face is positioned. Using the wrong modality for a task wastes labeling effort and produces a model that cannot answer the question you actually need it to answer.
Pro Tip: Before scoping an annotation project, write out the exact inference task your model needs to perform. Work backward from that task to select the annotation type. Annotating at a higher resolution than the task requires adds cost without adding model value.
For text-based tasks, annotation techniques in machine learning include span labeling, relation extraction tagging, and coreference resolution. Audio annotation adds speaker diarization and emotion tagging on top of transcription. Video annotation layers temporal tracking across frames, which multiplies the labeling effort significantly compared to static images.
Why does ground truth data quality define model performance?
Ground truth data is a curated, gold-standard labeled dataset used as an objective benchmark to assess other annotations and model outputs. It is the reference point against which everything else is measured. Without a verified ground truth subset, you have no reliable way to know whether your annotations are consistent or your model is actually learning the right patterns.
The role of ground truth in annotation quality assurance is specific. It serves three functions:
- Calibration baseline. New annotators label the ground truth set first. Their agreement rate with the verified labels reveals whether they have understood the guidelines.
- Drift detection. Running annotators against the ground truth set periodically catches label drift before it contaminates the full dataset.
- Model evaluation. The ground truth set provides an unbiased test surface that was never used in training.
“Annotation is more than tagging. It requires aligning labels with precise definitions that match model evaluation criteria.” — CVAT
Manual labeling delivers the highest accuracy for complex data requiring domain expertise. This is especially true in healthcare, where a misclassified lesion in a training image can propagate errors into a diagnostic model, and in autonomous driving, where a missed pedestrian label has direct safety implications.
Inter-annotator agreement is the metric that tells you whether your guidelines are working. If two trained annotators label the same sample differently at a high rate, the problem is almost never the annotators. The problem is the guideline. Fixing the guideline before scaling the annotation run saves significant rework.
Pro Tip: Reserve 3–5% of your dataset as a verified ground truth subset before annotation begins. Use it to measure annotator accuracy throughout the project, not just at the end.
How do you integrate annotation into AI training pipelines?
Effective annotation workflows follow a structured sequence. Skipping steps early creates compounding problems later. Here is the production-grade approach:
- Write annotation guidelines before labeling begins. Document every label category with definitions, edge cases, and visual examples. Ambiguous guidelines produce inconsistent labels at scale.
- Run a pilot labeling round on a small sample. Use 200–500 examples to stress-test the guidelines. Measure inter-annotator agreement. Revise the guidelines based on where disagreements cluster.
- Build a verified ground truth subset. Have senior annotators or domain experts label a representative sample. This becomes your quality benchmark for the full run.
- Scale with human-in-the-loop validation. Do not release annotators to label the full dataset without ongoing quality checks. Sample and review batches throughout the run.
- Integrate AI-assisted annotation where appropriate. Large language models and pre-trained models can generate candidate labels that human annotators verify. This accelerates throughput but requires programmatic validation to catch errors and hallucinations.
- Deliver in model-ready format. Validated labels should be exported in the format your training framework expects, whether that is COCO JSON, YOLO text files, or a custom schema.
Annotation protocols that include documented guidelines, pilot datasets, inter-annotator agreement checks, and a verified ground truth subset are the standard for production ML. Teams that skip the pilot round consistently report higher rework rates and longer overall project timelines.
The data-centric AI approach frames annotation quality as more impactful than model tuning. Spending an extra week refining annotation guidelines before a large labeling run typically produces better model outcomes than spending the same time adjusting hyperparameters after training. You can explore labeling methods in depth to match the right approach to your specific pipeline.
What are the biggest challenges in AI data annotation today?
Annotation at scale surfaces problems that small pilot runs hide. The most common challenges practitioners face include:
- Scalability and labor costs. High-volume annotation projects require large annotator pools, quality management infrastructure, and clear escalation paths for edge cases.
- Ambiguous or subjective data. Sentiment labels, toxicity classifications, and medical diagnoses involve genuine human disagreement. No guideline eliminates this entirely. The goal is to reduce it to an acceptable threshold.
- Label drift over time. Annotators’ interpretation of guidelines shifts subtly over long projects. Without periodic ground truth checks, drift accumulates undetected.
- Domain expertise requirements. Radiology images, legal documents, and financial instruments require annotators with specialized knowledge. General-purpose annotation vendors cannot reliably handle these tasks.
- Automated annotation quality. LLMs used for automated labeling augment human throughput but introduce hallucination risk. Every AI-generated label needs a validation layer before it enters a training set.
The emerging direction in 2026 is hybrid annotation: LLMs generate candidate labels, human annotators review and correct them, and programmatic checks flag statistical outliers. This model reduces per-label cost while maintaining the accuracy that fully automated annotation cannot yet guarantee. The best AI outcomes still start with high-quality data, not with the model architecture.
Key takeaways
Annotation quality is the single largest determinant of AI model performance, more so than model architecture or hyperparameter tuning.
| Point | Details |
|---|---|
| Annotation defines model ceiling | No amount of model tuning compensates for inconsistent or incorrect training labels. |
| Match annotation type to task | Bounding boxes, segmentation, keypoints, and tags each serve different inference tasks. |
| Ground truth is non-negotiable | A verified benchmark subset is required to detect label drift and measure annotator accuracy. |
| Pilot before scaling | A 200–500 sample pilot round catches guideline failures before they multiply across the full dataset. |
| Hybrid annotation is the current standard | LLM-assisted labeling accelerates throughput but requires human and programmatic validation at every stage. |
Annotation is an engineering discipline, not a labeling task
I have seen annotation treated as a commodity step that any vendor can handle at volume. That assumption is where most annotation projects go wrong. The real work is not the labeling itself. It is the guideline design, the ground truth construction, and the quality measurement infrastructure that runs throughout the project.
The teams that get annotation right treat it the way they treat software engineering: with version control on guidelines, regression testing against ground truth, and clear acceptance criteria before any batch is signed off. The teams that get it wrong treat it as a data entry task and discover the problem six months later when their model fails on a class it was supposedly trained on.
One thing I would push back on is the idea that AI-assisted annotation solves the quality problem. It solves the throughput problem. Quality still requires human judgment, especially for the edge cases that determine how a model behaves in production. If you are annotating datasets for a safety-critical application, no LLM-generated label should enter your training set without expert review.
The practitioners who build the best models are not the ones with the most sophisticated architectures. They are the ones who treat their training data as a product and maintain it with the same rigor they apply to their code.
— Oleg
How DOT data labs handles annotation at production scale
If your team is spending engineering cycles managing annotation vendors, resolving label inconsistencies, or rebuilding quality pipelines from scratch, that is time not spent on model development.

DOT Data Labs handles the full annotation supply chain for ML teams across automotive, healthcare, and finance applications. That includes guideline design, pilot runs, inter-annotator agreement measurement, ground truth construction, and final delivery in model-ready formats. Recent projects include 50,000 hours of talking-head video with aligned subtitles and a 32 million science Q&A dataset delivered in under 30 days. Explore DOT Data Labs’ data annotation services to see how a full-stack annotation partner accelerates your training data pipeline without adding internal overhead.
FAQ
What is annotation in AI, in simple terms?
Annotation in AI is the process of labeling raw data so machine learning models can learn from it. It transforms unstructured inputs like images, text, and audio into structured training examples with clear, machine-readable labels.
What are the most common types of AI annotation?
The most common types include classification tags, bounding boxes, semantic segmentation, keypoints, transcription, and named entity tagging. Each type produces a different supervision signal suited to a specific model task.
Why is ground truth data important in annotation?
Ground truth data is a verified benchmark dataset used to measure annotator accuracy and detect label drift. Without it, there is no objective way to confirm that your training labels are consistent or correct.
How does poor annotation affect AI model performance?
Poor annotation quality leads directly to inaccurate models. Data-centric AI research shows that optimizing annotation consistency has a greater impact on model accuracy than tuning model architecture alone.
Can AI tools automate the annotation process?
LLMs and pre-trained models can generate candidate labels to accelerate annotation throughput. However, automated labels require human review and programmatic validation before entering a training set, since AI-generated annotations carry hallucination risk.