
Why Fine-Tune AI Models: A Practitioner’s 2026 Guide

TL;DR:
- Fine-tuning adapts pre-trained models to specific tasks using curated, high-quality data to achieve domain-specific performance. It is most effective when output consistency and behavior stability are critical, and less suitable for frequently changing facts or personalization needs. Alternatives like prompt engineering and RAG should be considered first to avoid unnecessary costs and complexity.
Fine-tuning is defined as the process of adapting a pre-trained AI model to a specific task or domain by continuing its training on a curated, task-relevant dataset. This is the core technique behind why AI teams at biotech firms, financial institutions, and enterprise software companies achieve domain-specific performance that general-purpose models like GPT-4o or Llama 3 cannot match out of the box. Understanding why fine-tune AI models matters starts with recognizing that transfer learning improves task-specific performance when data is limited, making fine-tuning far more practical than full retraining. This guide covers the benefits, the tradeoffs, the methods, and the decision criteria you need to apply it correctly.
Why fine-tune AI models: core benefits and performance gains
Fine-tuning’s primary value is specialization. A general-purpose language model trained on internet-scale data performs adequately across many tasks, but domain-adapted models outperform generic ones in specialized tasks while lowering latency and training overhead. For a biotech research assistant processing clinical trial summaries, or a financial risk model classifying regulatory filings, that performance gap is the difference between a production-ready tool and an unreliable prototype.
The benefits of fine-tuning AI extend well beyond raw accuracy:
- Domain accuracy. Fine-tuned models learn specialized terminology, entity types, and reasoning patterns that general models handle inconsistently.
- Output consistency. Style, tone, and schema compliance become baked into the model weights, not dependent on prompt quality.
- Lower inference latency. A smaller, specialized model typically runs faster than prompting a large general model with extensive context.
- Reduced compute costs. Fine-tuning on an existing checkpoint requires far less compute than training from scratch, and enterprises achieve competitive edge through proprietary data without rebuilding model architecture.
- Faster time-to-production. Starting from a capable base model cuts weeks off the development cycle compared to building domain models from scratch.
Pro Tip: Before committing to fine-tuning, run a structured prompt engineering evaluation first. If a well-crafted system prompt gets you 80% of the way to your target behavior, fine-tuning the remaining 20% may not justify the cost.
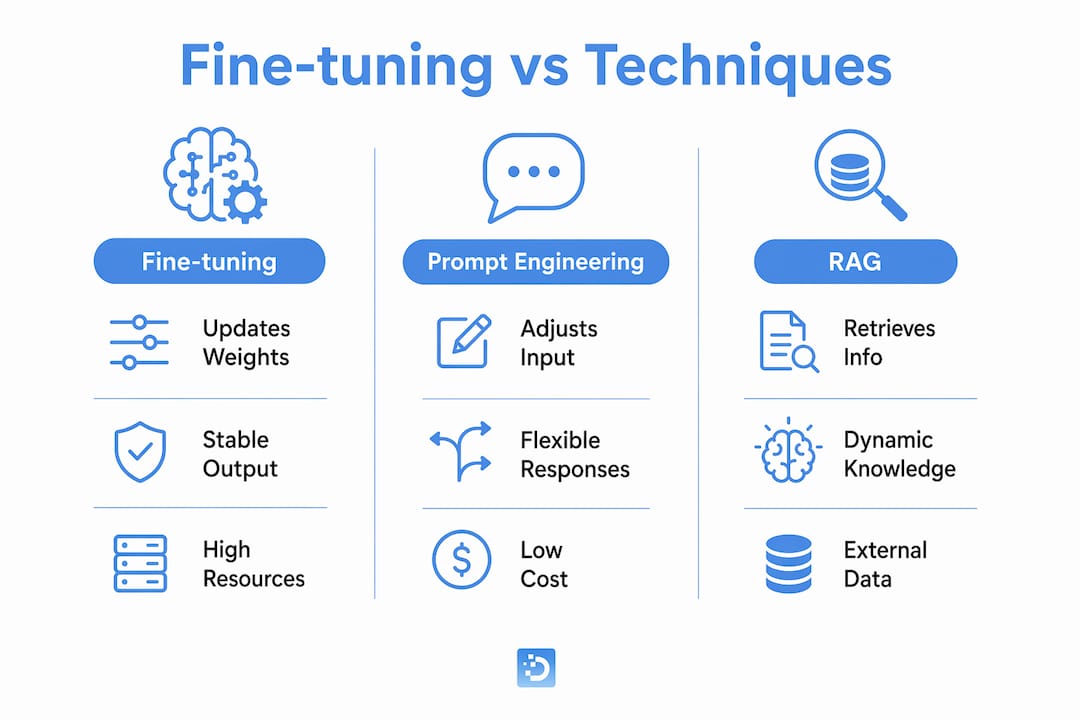
How fine-tuning compares to prompt engineering and RAG

These three techniques solve different problems. Conflating them is the most common mistake practitioners make when planning model adaptation.
| Technique | How it works | Best for | Limitations |
|---|---|---|---|
| Fine-tuning | Updates model weights on curated data | Stable behavior, format, tone, domain style | Costly to update; risks forgetting prior capabilities |
| Prompt engineering | Modifies input instructions at inference time | Fast iteration, general task guidance | Inconsistent across users and edge cases |
| Retrieval-augmented generation (RAG) | Injects external knowledge at inference | Dynamic facts, frequently updated content | Adds latency; retrieval quality determines output quality |
Fine-tuning changes the model itself. Prompt engineering changes what you say to the model. RAG changes what information the model sees. Each operates at a different layer of the stack.
The practical implication: fine-tuning is most valuable when behavioral consistency and output format stability are critical, not for dynamic knowledge updates. If your use case involves frequently changing facts, per-user personalization, or rapid behavior iteration, RAG or prompt engineering will serve you better and cost less. Fine-tuning a model to “know” current stock prices is the wrong tool. Fine-tuning a model to always output structured JSON in a specific schema, using your company’s terminology, is exactly right.
Prompt engineering and retrieval should be exhausted before fine-tuning to avoid unnecessary costs and complexity. This is not a knock on fine-tuning. It is a sequencing principle that saves teams months of work.
Best practices for fine-tuning AI models effectively
Getting fine-tuning right is mostly a data problem, not a modeling problem. Dataset curation and preprocessing consume the majority of fine-tuning project effort and strongly determine success. Here is a structured approach that holds up in production:
- Select the right base model. Choose a pre-trained model whose architecture and pretraining domain align with your target task. A code-specialized model is a better starting point for a code generation task than a general chat model.
- Curate a high-quality dataset. 100 to 500 quality examples outperform thousands of noisy ones. Every example should reflect the exact input-output behavior you want the model to learn. See DOT Data Labs’ guidance on fine-tuning data principles for curation frameworks that apply directly to this step.
- Apply an 80/10/10 split. Allocate 80% of examples to training, 10% to validation, and 10% to a held-out test set. This split catches overfitting before deployment.
- Use parameter-efficient methods. Techniques like LoRA and QLoRA reduce compute and memory demands by updating only a subset of model weights. LoRA (Low-Rank Adaptation) inserts trainable matrices into transformer layers, enabling fine-tuning on consumer-grade GPUs without touching the full parameter space.
- Build an evaluation harness before training. Define your success metrics, edge case tests, and regression checks before you run a single training step. This prevents the common failure mode of optimizing for training loss while degrading real-world performance.
- Monitor for catastrophic forgetting. Fine-tuning on narrow data can degrade a model’s general capabilities. Run your eval harness on held-out general benchmarks alongside domain-specific ones.
Pro Tip: For most teams, data formatting is where fine-tuning projects stall. Review DOT Data Labs’ training data formatting guide before you start labeling. Getting the input-output structure right from the beginning saves significant rework.
The table below summarizes the key method choices and their tradeoffs:
| Method | Resource requirement | Best use case |
|---|---|---|
| Full fine-tuning | High (all weights updated) | Maximum domain adaptation, large compute budgets |
| LoRA | Low to medium | Most production use cases; consumer GPU compatible |
| QLoRA | Very low | Quantized models; edge deployment or limited hardware |
When fine-tuning is the right solution
Fine-tuning is justified when three conditions are true: the behavior you need is stable and well-defined, the volume of inference is high enough to amortize the training cost, and output consistency matters more than flexibility.
Concrete scenarios where fine-tuning wins:
- A legal document classifier that must apply a fixed taxonomy consistently across thousands of filings per day.
- A customer support model trained on your product’s specific terminology, tone guidelines, and escalation patterns.
- A medical coding assistant that must output ICD-10 codes in a precise format with no hallucinated entries.
Fine-tuning is the wrong choice when:
- Facts change frequently and the model needs to reflect current information (use RAG instead).
- You need per-user personalization at inference time (fine-tuning bakes in population-level behavior, not individual preferences).
- Your behavior requirements are still evolving. Each behavioral change requires retraining, which is costly and time-consuming.
Operationally, fine-tuning is a batch specialization process. It is not continuous learning. You commit to a version of the model, deploy it, and run a full MLOps cycle when updates are needed. Teams that treat it as a lightweight, iterative process burn through compute budgets quickly. The ongoing MLOps cycle of retraining, validation, and deployment is a real operational commitment, and it should factor into your build-versus-buy calculus for training data as well.
Key takeaways
Fine-tuning AI models delivers the most value when behavioral consistency, domain-specific formatting, and inference efficiency matter more than knowledge freshness or flexibility.
| Point | Details |
|---|---|
| Fine-tuning defined | Adapts pre-trained model weights to a specific task using curated, domain-relevant data. |
| Data quality over quantity | 100 to 500 high-quality examples outperform thousands of noisy ones; use an 80/10/10 split. |
| Use LoRA or QLoRA | Parameter-efficient methods cut compute and memory costs without sacrificing domain performance. |
| Exhaust alternatives first | Prompt engineering and RAG should be evaluated before committing to fine-tuning. |
| Operational commitment | Fine-tuning requires a full MLOps cycle for each update; plan for retraining costs upfront. |
The part most teams get wrong
Most fine-tuning failures I have seen are data failures dressed up as model failures. Teams spend weeks selecting the right base model and tuning hyperparameters, then hand off a hastily assembled dataset with inconsistent formatting, mislabeled examples, and no validation split. The model trains. The evals look acceptable. Then it falls apart on real traffic.
The counterintuitive truth about fine-tuning is that the modeling part is now largely solved. LoRA and QLoRA have made parameter-efficient adaptation accessible to teams without dedicated ML infrastructure. What remains hard is the data work: defining the right input-output pairs, labeling them consistently, catching edge cases before they become training signal, and maintaining that dataset as your product evolves.
I have also seen the opposite failure: teams fine-tuning when they should be prompting. A well-structured system prompt with a few-shot examples often achieves 85 to 90% of what a fine-tuned model would deliver, at a fraction of the cost and with the flexibility to iterate in hours rather than weeks. Fine-tuning earns its place when you have crossed that threshold and need the last 10 to 15% of performance, or when you are running at a scale where inference cost savings justify the training investment.
The teams that get this right treat fine-tuning as a deliberate, scoped decision with a clear evaluation framework, not a default response to model underperformance.
— Oleg
How DOT Data Labs accelerates your fine-tuning projects
Fine-tuning is only as good as the data behind it. DOT Data Labs builds the training datasets that make fine-tuning projects succeed: sourced, cleaned, labeled, and delivered in model-ready formats to your exact specifications.

Whether you need a one-off custom dataset scoped to your domain or an ongoing data pipeline feeding your training infrastructure, DOT Data Labs handles the full data supply chain. Start with understanding what training-ready data actually requires, then explore how DOT Data Labs can deliver it at scale. Teams across the US, Europe, and Asia use DOT Data Labs to cut data preparation time and ship fine-tuned models faster. Visit dotdatalabs.ai to scope your next dataset project.
FAQ
What does fine-tuning an AI model mean?
Fine-tuning is the process of continuing a pre-trained model’s training on a smaller, task-specific dataset to improve its performance on a target domain or task. It updates model weights rather than modifying prompts or adding external retrieval.
How many examples do you need to fine-tune a model?
100 to 500 high-quality examples typically outperform larger noisy datasets for fine-tuning. Data quality and consistent formatting matter more than raw volume.
What is the difference between fine-tuning and RAG?
Fine-tuning updates model weights for stable behavioral changes, while retrieval-augmented generation (RAG) injects external knowledge at inference time without changing the model. RAG is better for frequently updated facts; fine-tuning is better for consistent style and format.
What is LoRA and why does it matter for fine-tuning?
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning method that updates only a small subset of model weights, reducing compute and memory requirements significantly. It enables fine-tuning on consumer-grade hardware without full model retraining.
When should you not fine-tune an AI model?
Fine-tuning is not suited for use cases requiring frequent knowledge updates, per-user personalization, or rapidly changing behavior requirements. In those cases, prompt engineering or RAG delivers better results at lower cost and operational overhead.