
What is training-ready data? Criteria and best practices

TL;DR:
- Training-ready data incorporates thorough preparation, labeling, formatting, and certification for specific models.
- Key criteria include completeness, accuracy, consistency, representativeness, and documented provenance.
- Achieving and maintaining data readiness is an ongoing process that adapts to evolving models and use cases.
Most ML engineers assume that cleaning a dataset is enough to make it usable for model training. Run a deduplication pass, drop nulls, normalize the schema, and ship it. That assumption is expensive. Cleaned data and training-ready data are not the same thing, and confusing the two leads to models that underperform, overfit, or fail silently at inference. True training-readiness is a certified, multidimensional standard that covers labeling, formatting, representativeness, governance, and use-case alignment. This article breaks down exactly what that standard requires and how to meet it.
Key Takeaways
| Point | Details |
|---|---|
| Definition matters | Training-ready data is fully prepared, labeled, formatted, and optimized for AI models, not just cleaned. |
| Multiple criteria | Completeness, uniqueness, format compliance, and provenance are all essential for true readiness. |
| Process over state | Certification-based, ongoing processes ensure data remains aligned with evolving model needs. |
| Quality beats quantity | High-quality training-ready data delivers proven, substantial accuracy gains over simply having more data. |
Defining training-ready data
The term “training-ready” gets used loosely, but it has a precise meaning in production ML contexts. Training-ready data is data that has undergone comprehensive preparation to be directly usable for training or fine-tuning AI and ML models, including cleaning, labeling, formatting, and optimization for model architectures. That last part matters. Optimization for model architectures means the data is not just clean but structured in ways that match how the model actually consumes input during training.
Think of it like a supply chain. Raw data is raw material. Cleaned data is processed material. Training-ready data is a finished component, built to spec, tested, and certified for assembly. You would not install an untested part in a critical system, and you should not feed uncertified data into a model you plan to deploy.
Data readiness frameworks define levels of maturity that make this progression concrete:
- Level 1: Raw — unprocessed, unvalidated, inconsistent formats
- Level 2: Cleaned — nulls handled, obvious errors removed, basic normalization applied
- Level 3: Labeled — annotations added, classes defined, intent or entity tags applied
- Level 4: Feature-engineered — derived fields, embeddings, domain-specific transformations
- Level 5: Fully AI-ready — formatted for scalable training, such as sharded HDF5 or JSONL, with documented lineage
Most teams operate at Level 2 or 3 and call it done. True training-readiness sits at Level 5. The gap between Level 3 and Level 5 is where most model performance problems originate.
“AI-ready data is not a state you reach once. It is a certification you earn repeatedly, for each model and each use case.”
Building a high-quality dataset for AI training requires treating readiness as a documented, verifiable outcome rather than a gut feeling. That means defining acceptance criteria before you build the pipeline, not after.
The data pre-processing steps you choose also depend heavily on your target architecture. A fine-tuning dataset for a causal language model has different formatting requirements than a classification dataset or a RAG retrieval corpus. Readiness is always relative to the downstream task.
Key criteria and components of training-ready data
Building on the definition, it is essential to understand what differentiates truly training-ready data from simply cleaned or labeled datasets. The distinction comes down to a specific set of measurable criteria.
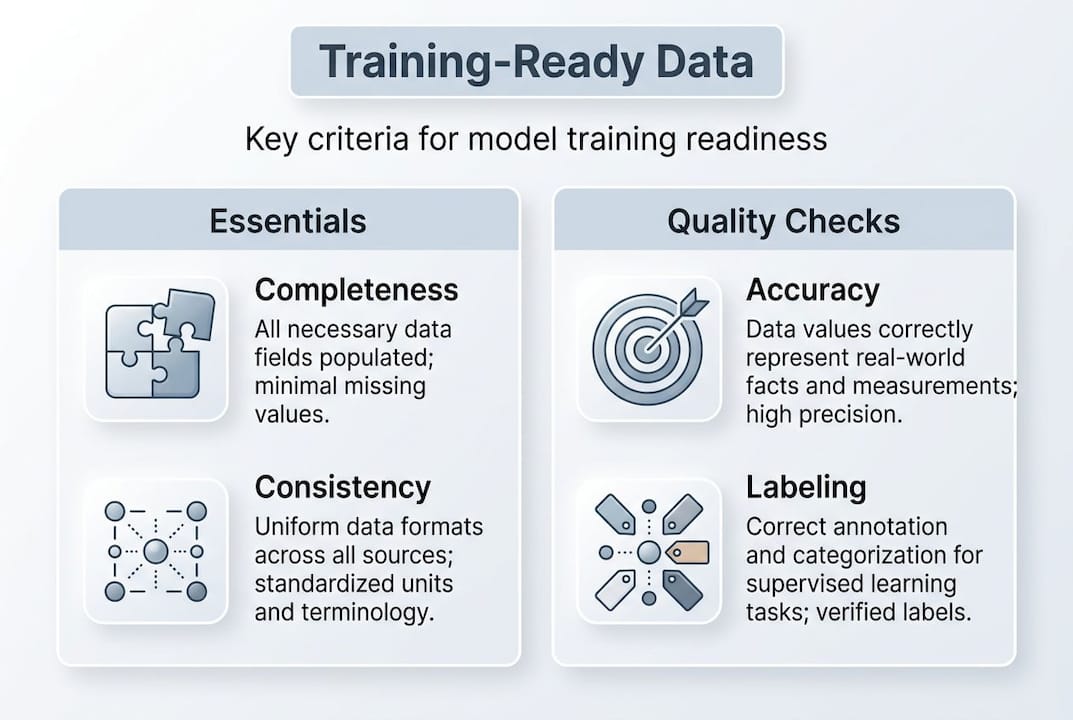
Essential criteria for data readiness include completeness above 95% for key fields, consistency across formats and schemas, accuracy validated against business rules, uniqueness through deduplication, timeliness, representativeness across demographic and domain diversity, proper labeling, format compliance such as JSONL for fine-tuning, and documented lineage and provenance.

| Criterion | What it means | Why it matters |
|---|---|---|
| Completeness | >95% fill rate on key fields | Missing values create training gaps |
| Consistency | Uniform formats and schemas | Prevents silent parsing errors |
| Accuracy | Validated against ground truth | Garbage in, garbage out |
| Uniqueness | Near-duplicate removal | Reduces memorization and bias |
| Representativeness | Balanced class and domain coverage | Prevents skewed generalization |
| Labeling quality | Correct, consistent annotations | Directly drives supervised performance |
| Format compliance | JSONL, CSV, or model-specific schemas | Ensures pipeline compatibility |
| Provenance | Documented data origin and transformations | Enables auditing and recertification |
Each of these criteria interacts with the others. A dataset can be 99% complete but still fail on representativeness if all the examples come from a single demographic or writing style. A dataset can have perfect labeling but fail on format compliance if the field names do not match what the training framework expects.
Key attributes to verify before certifying any dataset:
- Field-level completeness rates documented and above threshold
- Schema validated against the target model’s expected input format
- Label distribution reviewed for class imbalance
- Duplicate rate measured using both exact and fuzzy matching
- Data provenance recorded with transformation history
Pro Tip: Run a small pilot training job on 5% of your dataset before committing to full training. This surfaces format mismatches, label errors, and schema issues early, when they are cheap to fix.
Use the AI data quality checklist to systematically verify each criterion before moving data into a training pipeline. Pairing that with a structured dataset cleansing process ensures you are building on a solid foundation rather than discovering problems mid-run.
Proven methodologies for preparing training-ready datasets
With clear criteria in mind, the next challenge becomes how to actually prepare and certify training-ready datasets efficiently and at scale. The good news is that a well-documented set of methodologies exists, and teams that apply them consistently see dramatically better outcomes.
Key methodologies include heuristic filtering based on length and duplication, model-based quality classification using tools like fastText classifiers, deduplication through exact hash matching and locality-sensitive hashing for near-duplicates, template application and loss masking for LLMs, data blending for balanced representation, and synthetic generation with LLM jury filtering.
Here is how these steps fit into a practical pipeline:
- Heuristic filtering — Remove examples that are too short, too long, or structurally malformed. Set minimum and maximum token thresholds based on your model’s context window.
- Model-based classification — Use a lightweight classifier to score each example for quality, relevance, and domain fit. fastText works well here because it is fast enough to run at scale.
- Deduplication — Apply exact hash matching first, then LSH for near-duplicates. This step alone can eliminate 15 to 30% of a raw dataset that would otherwise cause memorization artifacts.
- Template application and loss masking — For instruction-tuned LLMs, apply your chat template consistently and mask the prompt tokens so the model only learns to predict completions, not inputs.
- Data blending — Mix sources intentionally to achieve balanced domain and style coverage. Unblended datasets from a single source tend to produce models that generalize poorly.
- Synthetic generation with jury filtering — Generate synthetic examples using a capable LLM, then filter them with a panel of smaller models or a scoring rubric to remove low-quality outputs.
| Approach | Best for | Limitation |
|---|---|---|
| Heuristic filtering | Fast, scalable first pass | Misses semantic quality issues |
| Model-based classification | Semantic quality scoring | Requires a trained classifier |
| LSH deduplication | Near-duplicate removal at scale | Approximate, not exact |
| Synthetic generation | Filling coverage gaps | Risk of policy drift without human data |
Automating deduplication and filtering, validating with holdout tests, and monitoring for data drift are the operational habits that separate teams shipping reliable models from those stuck in endless retraining cycles. An 80% pass rate after filtering is typical for production pipelines, meaning you should expect to discard roughly one in five raw examples.
Pro Tip: Build your data preprocessing workflow as a versioned, reproducible pipeline from day one. Every transformation should be logged so you can trace any model behavior back to a specific data decision.
Investing in a well-structured approach to formatting training-ready data pays dividends across every training run, not just the first one.
Critical challenges, pitfalls, and nuances in data readiness
Even with best practices, achieving and maintaining data readiness presents persistent and nuanced obstacles. Some of the most damaging problems are the ones you do not see until the model is already in production.
Template mismatch is one of the most insidious failure modes. When the chat template applied during fine-tuning does not match the one used at inference, loss decreases normally during training but the model fails to produce coherent outputs when deployed. The training metrics look fine. The model is broken. This is a silent structural failure, and it is more common than most teams admit.
Common pitfalls to watch for:
- Benchmark leakage — Training data that overlaps with evaluation benchmarks inflates reported accuracy and produces models that do not generalize to real inputs
- Policy drift in synthetic data — Iterative synthetic generation without human data injection causes the model’s outputs to drift from the original intended behavior; mixing in 10 to 20% human-authored examples mitigates this
- Class imbalance — Overrepresented categories cause overfitting on majority classes and underfitting on minority ones, which is especially damaging in classification and entity recognition tasks
- Missing loss masking — Failing to mask prompt tokens during instruction tuning forces the model to predict both prompt and completion, which degrades the quality of completion learning
- Stale data — Data that was training-ready six months ago may no longer meet current standards if the model architecture or task requirements have changed
“Cleaning data is necessary but not sufficient. A perfectly clean dataset can still be unrepresentative, ungoverned, and completely wrong for the target use case.”
Data readiness is use-case-specific certification, not a static state. A dataset certified for sentiment classification is not automatically ready for instruction tuning. Each new use case requires its own readiness assessment.
Applying structured AI data structuring methods from the start reduces the surface area for these failures. When your schema is designed with the target model in mind, many of these pitfalls become visible during pipeline validation rather than post-deployment.
Why training-ready data drives real-world AI model performance
Putting these insights together, it is clear why enterprises and ML engineers focus intently on readiness for real model performance gains. The evidence is not anecdotal.
High-quality training data yields 15 to 30% accuracy gains over larger but noisier datasets. The DCLM paper demonstrated a 6.6 percentage point improvement simply by applying model-based filtering to the training corpus, with no architectural changes. The model did not get bigger. The data got better.
Practical benchmarks for dataset sizing:
- 1,000 to 5,000 examples: effective for tone and style adaptation
- 5,000 to 20,000 examples: sufficient for domain adaptation tasks
- 20,000 or more: needed for broad capability expansion or new task categories
Quality consistently outperforms quantity across these ranges. A 2,000-example dataset with verified labels, balanced representation, and correct formatting will outperform a 20,000-example dataset scraped without curation.
Why does this happen? Noisy data forces the model to learn noise as signal. Every low-quality example the model trains on competes with the high-quality examples for gradient updates. The model has no way to distinguish between them. It learns a weighted average of everything it sees, and if a significant portion of what it sees is wrong, the learned weights reflect that.
Benefits of investing in training-ready data:
- Faster convergence — Clean, well-formatted data reduces the number of training steps needed to reach target performance
- Lower compute cost — Fewer training steps and less retraining means lower GPU hours per model version
- More predictable results — Certified data produces consistent outcomes across training runs, making experiments more interpretable
- Reduced post-deployment failures — Data that has been validated against the target use case produces models that behave as expected in production
Explore the role of datasets in AI success to see how these performance dynamics play out across different model types and deployment contexts.
The uncomfortable truth: why data readiness is a moving target
You might read this article and walk away thinking data readiness is a checklist you complete once and file away. It is not. The benchmark for what counts as “ready” shifts every time a new model architecture emerges, every time your use case evolves, and every time your production data distribution drifts.
Data readiness evolves with model needs, and certification models make that evolution evidence-based and repeatable across use cases. That is the key insight most teams miss. They treat readiness as a property of the data itself rather than a relationship between the data and the model it is meant to train.
A dataset certified for GPT-style causal language modeling may need significant rework for a retrieval-augmented generation pipeline. A dataset that was representative in 2024 may be stale by mid-2026 if the underlying domain has shifted. Governance and ongoing assessment are not optional add-ons. They are core components of any serious data readiness program.
At Dot Data Labs, we treat every dataset as a living artifact that requires versioning, recertification triggers, and documented lineage. The teams that build this discipline early are the ones that ship reliable models consistently, not just on the first run.
Accelerate your AI with certified training-ready datasets
If you are building AI systems that need to perform reliably in production, the quality of your training data is the single highest-leverage variable you control. Every methodology described in this article requires structured, schema-consistent, certified data to execute properly.

At Dot Data Labs, we build large-scale, machine-ready datasets designed specifically for LLM fine-tuning, domain adaptation, RAG pipelines, and classification models. Our production pipelines cover acquisition, structuring, deduplication, labeling, and format compliance from end to end. Start with our machine-ready dataset guide to understand how certified datasets are built, or go straight to formatting training-ready data for hands-on implementation guidance. When you are ready to move faster, Dot Data Labs can build the dataset your model actually needs.
Frequently asked questions
What is the difference between data quality and training-readiness?
Data quality refers to static metrics like completeness and accuracy, while training-readiness adds requirements like governance, architecture alignment, and certification for a specific model use case. Clean data can still be unrepresentative and unready.
How much does high-quality training-ready data improve model accuracy?
High-quality data can boost model accuracy by 15 to 30% compared to larger but noisier datasets, with documented cases showing 6.6 percentage point gains from filtering alone.
What are the most important steps to prepare data for model training?
The core steps are heuristic filtering, model-based quality classification, deduplication and loss masking, data blending, and automated validation through holdout tests before any model training begins.
Is data readiness a one-time process?
No. Data readiness must be continuously assessed and recertified as model architectures, use cases, and data distributions evolve over time.
Recommended
- How to Format Training-Ready Data for AI Fine-Tuning
- Machine-Ready Dataset Guide: Build Optimized AI Training Sets – Dot Data Labs – High-Quality Data for Training AI Models
- Dot Data Labs — High-Quality Data for Training AI Models — Providing datasets for AI training
- Large-Scale Data Collection Guide: Steps for Model Training