
What is machine-ready data? The key to scalable AI

TL;DR:
- Machine-ready data is high-quality, structured, and governed to ensure reliable AI model performance across multiple projects. It includes traceability, versioning, schema enforcement, and ongoing validation, not just clean or structured data. Adopting a rigorous, end-to-end approach to data readiness reduces deployment risks, technical debt, and ensures compliance and trustworthiness in AI workflows.
Models trained on data that looks clean but isn’t fully prepared can fail in production in ways that are expensive and hard to debug. You’ll see it in silent accuracy drops after retraining, in regulatory audits that uncover unlabeled exceptions, or in pipelines that break when source schemas shift. AI-ready data is essential for trustable outputs and scalability in AI pipelines, yet most teams underestimate what “ready” actually requires. This guide defines machine-ready data precisely, breaks down its core components, and gives you a practical framework for achieving and maintaining it at scale.
Key Takeaways
| Point | Details |
|---|---|
| Beyond basic cleaning | True machine-ready data requires structure, traceability, and operational governance, not just removal of errors. |
| Context-specific | Data requirements for training vary across ML models and use cases—one size does not fit all. |
| Supports scalability | Prepared data enables reproducible, automated ML pipelines and faster deployments at scale. |
| Evolving standards | Fairness, labeling, and drift monitoring are now core to machine-ready data evaluations. |
| Operational discipline | Versioned contracts, validation gates, and governance processes help prevent last-minute data failures. |
What does machine-ready data mean?
With the risks of unreliable data established, let’s clarify what “machine-ready” actually means, and what sets it apart from simply cleaned or structured data.
Most data teams are comfortable with the idea of clean data: no nulls, no duplicates, consistent formats. Machine-ready data is a different standard. IBM describes AI-ready data as high-quality, accessible, and trusted information that is prepared, structured, and governed to be usable by AI systems at scale.
Machine-ready data doesn’t just pass a cleaning checklist. It is auditable, versioned, schema-enforced, and traceable from source to model input. It will work reliably across every training run, not just the first one.
That distinction matters most when you are running multiple ML projects against the same data sources, or retraining models on a schedule. Clean data may work once. Machine-ready data works every time, with evidence to prove it. The ability to accelerate machine learning with high-quality datasets depends entirely on this level of rigor. The key ingredients are:
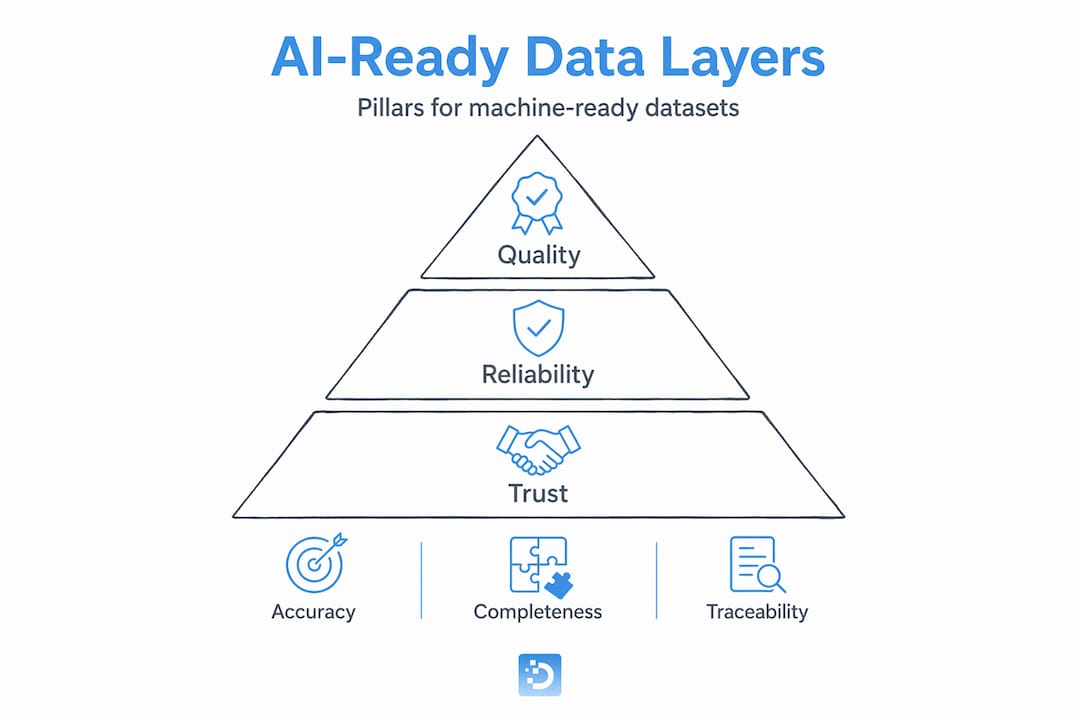
- Quality: Accuracy, completeness, and consistency validated against agreed standards.
- Structure: Data formatted and aligned to the schema your model expects as input.
- Governance: Provenance, lineage, versioning, and compliance documentation for every change.
- Trust: An auditable record that confirms the data will behave as expected in production.
Each of these properties needs to hold not just at initial delivery but on an ongoing basis as sources change and models evolve.
Key components of machine-ready data
Now that we understand what machine-ready data is, here’s what it must include to truly deserve that definition, for your models and for compliance teams alike.
DataHub identifies the pillars of AI-ready data as quality, reliability, and trust, anchored in accuracy, completeness, consistency, structured formatting, schema alignment, governance, traceability, and pipeline reliability. Think of these as four non-negotiable layers.

| Layer | What it covers | Common failure mode |
|---|---|---|
| Quality | Accuracy, completeness, consistency | Incomplete records, conflicting values |
| Structure | Schema alignment, format, encoding | Mismatched field types, missing columns |
| Governance | Lineage, versioning, compliance | No audit trail, unknown data origin |
| Pipeline reliability | Stability across source and schema changes | Broken pipelines after upstream updates |
Here is how to validate each layer in practice:
- Audit quality at the field level. Check for accuracy (values match ground truth), completeness (no critical nulls), and consistency (same entity represented the same way across tables). Use statistical profiling on every ingestion run.
- Enforce schema contracts. Define and version a strict schema for each model input. Reject or flag records that deviate. Tools like Great Expectations or dbt tests work well here.
- Document lineage from day one. Every transformation, join, or enrichment step should be logged. Teams reviewing model failures months later need to trace exactly what the training data contained and when it changed.
- Test pipeline stability against source drift. Simulate schema changes in your sources and confirm your pipeline surfaces them as alerts, not silent failures.
Reviewing your training-ready data criteria against these layers is a good starting point, and a machine-ready dataset optimization review can surface gaps that internal teams often miss.
Pro Tip: Treat your training dataset as a versioned product with a schema contract. When a downstream model is certified against v2.3 of a dataset, no one should be able to quietly push v2.4 without a version bump and a revalidation gate.
How readiness varies by use case
While the fundamentals are universal, not all models or business goals require the same standard. Here’s why your team’s use case matters.
Data readiness is use-case-specific. Data that is entirely adequate for business intelligence dashboards can be deeply unsuitable for ML training, and data prepared for a classification model may be the wrong format for a generative model. This is one of the most common mistakes teams make: they promote a dataset from BI to ML without re-evaluating it for the new context.
| Use case | Label requirement | Noise tolerance | Key risk |
|---|---|---|---|
| Business intelligence | None | Moderate | Aggregation errors |
| Predictive ML model | Precise, complete labels | Low | Label leakage, class imbalance |
| Generative model (LLM) | Instruction-response pairs, format-specific | Very low | Contamination, format mismatch |
The requirements differ radically because the failure modes are different. A predictive churn model fails quietly when labels are noisy, producing overconfident predictions that nobody flags until customer outcomes disagree. A fine-tuned language model fails loudly when instruction formats are inconsistent, but that visibility can mask subtler alignment problems. Review a detailed data quality checklist for LLM fine-tuning if your team is working on generative models specifically.
Key factors that vary by use case:
- Label granularity and completeness requirements.
- Acceptable class imbalance ratios.
- Time windowing and temporal ordering constraints.
- Allowable noise levels in input features.
- Regulatory requirements around data origin.
Pro Tip: Before promoting a dataset to training, ask your team: “Where will this fail in production?” Work backward from your most likely failure mode, whether that’s label leakage, distribution shift, or class imbalance, and validate against that specific risk explicitly.
Advanced readiness: Beyond basic quality checks
With those context-sensitive differences in mind, many teams miss the newest requirements that make data truly machine-ready for modern ML workloads.
ML readiness goes beyond generic quality metrics to include AI-specific concerns such as fairness, mislabeled data, and evolving standards that did not exist in classical data engineering. These are the gaps that most checklist-based approaches overlook.
The most expensive data problems are the ones you don’t discover until after deployment: a training set that was accurate but unrepresentative, labels that were consistent but biased, or features that were complete but stale.
The evolving metrics your team should track include:
- Timeliness: Is the data current enough to represent the production environment the model will operate in?
- Representativeness: Does the dataset reflect the full distribution of inputs the model will encounter, including edge cases?
- Label quality: What is the inter-annotator agreement score? What percentage of labels were reviewed by a second annotator?
- Fairness and bias: Are protected attributes handled correctly? Does label distribution skew by demographic group?
- Drift detection: Is there a baseline distribution snapshot so you can detect when incoming data diverges?
- Compliance traceability: Can you prove the dataset’s origin and consent status if audited?
These metrics are not yet standardized across the industry, which means teams building internal pipelines often miss several of them until a model incident forces the issue. A structured data preprocessing workflow for AI that incorporates these checks from the start saves significant remediation time later.
How to operationalize machine-ready data in your ML workflow
Finally, these high standards must be part of a scalable, repeatable process. Here’s how mature teams achieve that.
Operationalizing machine-ready data means versioned products, enforced schema and semantic contracts, data-quality gates, and continuous validation for pipeline drift. None of those elements work in isolation. Here is how to build them together:
- Define schema contracts per model. Document the expected input schema, data types, value ranges, and label taxonomy for each model. Version these contracts alongside your model code.
- Automate quality gates in the pipeline. Ingestion pipelines should run quality checks before data is written to the training store, not after. Any record that fails a gate gets flagged, quarantined, or rejected, never silently passed through.
- Assign data ownership. Every dataset should have a named owner or steward responsible for its health. Without ownership, no one acts when drift alerts fire.
- Build continuous validation. Deploy monitoring that compares incoming data distributions against your training baseline and triggers alerts or retraining workflows when drift crosses a threshold.
Key practices that separate mature pipelines from fragile ones:
- Treat every schema change as a breaking change until proven otherwise.
- Log every transformation in a lineage graph, not just the final output.
- Run shadow validation on new data sources before using them in production training.
This approach to your data transformation process is what separates teams that ship reliable models from teams that constantly chase unexplained regressions.
What most teams miss about machine-ready data
Stepping back, here’s what we’ve learned from seeing dozens of teams struggle, or succeed, at the threshold of deployment.
Most production breakdowns do not come from bad data in an obvious sense. They come from hidden schema mismatches between training and serving, from unlabeled exception cases that the annotation team never encountered, and from lineage gaps that make it impossible to audit what changed between training runs. These problems are undetectable until a model is live.
The teams that consistently ship reliable models share one trait: they treat their data as a first-class product. Not an input to the “real” work of modeling, but an artifact with its own versioning, ownership, quality SLAs, and release criteria. That shift in mindset changes everything. It means data problems get caught before training, not after deployment.
Strict readiness processes also reduce long-term technical debt significantly. Every hour invested in schema contracts and lineage documentation early pays back many times over when you need to retrain, audit, or explain a model six months later. The teams that skip this step are the same teams rebuilding pipelines from scratch after every major incident. Explore how better data for smarter AI results compounds over time when readiness is treated as a process, not a one-time event.
Take the next step toward truly machine-ready data
If you’re ready to strengthen your data strategy, here’s where to start.
Building machine-ready pipelines in-house requires specialized tooling, annotation capacity, and governance expertise that most ML teams are not set up to own entirely. The investment is real, and the mistakes are costly.

DOT Data Labs builds auditable, versioned, compliance-scoped training datasets and data pipelines for ML teams that need production-grade data without managing multiple vendors. Whether you need a single custom dataset delivered to exact specifications, or a continuous pipeline feeding labeled, validated data into your training infrastructure, the full data supply chain is covered. Review AI-driven model training solutions or dig into training-ready data criteria and best practices to see how the process works end to end.
Frequently asked questions
Is machine-ready data the same as clean data?
No. AI-ready data is prepared, structured, and governed, not just cleaned. Machine-ready data includes schema enforcement, traceability, versioning, and governance that go well beyond removing nulls or duplicates.
How can I tell if my data is machine-ready for a new ML model?
Check schema alignment, label completeness, lineage documentation, and use-case-specific quality standards. Readiness is contextual, so data that qualified for a previous model may not meet the requirements of a new one without re-evaluation.
What are the main risks of using non-machine-ready data in production?
Expect model instability, silent accuracy degradation, failed retraining runs, and compliance exposure. Insufficient data readiness produces unstable outcomes regardless of how well the model architecture is designed.
Does machine-ready data guarantee model fairness?
Not automatically. Readiness evaluations should include fairness and class balance checks, but fairness requires deliberate design decisions in labeling, sampling, and bias auditing, not just a quality checklist.
Recommended
- AI-Ready Datasets: How to Accelerate Machine Learning
- What is training-ready data? Criteria and best practices
- Dot Data Labs — High-Quality Data for Training AI Models — Providing datasets for AI training
- Machine-Ready Dataset Guide: Build Optimized AI Training Sets – Dot Data Labs – High-Quality Data for Training AI Models