
What is large-scale data? A guide for AI leaders

TL;DR:
- Large-scale data in machine learning exceeds standard processing capacities and encompasses volume, velocity, variety, and veracity. Effectively managing, curating, and optimizing data quality is crucial for building high-performing models, as size alone does not guarantee success. Implementing robust pipelines, governance, and domain-specific curation significantly enhances AI model outcomes.
Most ML teams assume that more data automatically means better models. It’s an intuitive belief, but it’s only partially true. Large-scale data in machine learning refers to datasets that exceed the processing capacity of standard tools, characterized by four dimensions: volume, velocity, variety, and veracity. Getting those four dimensions right, not just stacking terabytes, is what separates teams that ship performant models from teams that burn compute budgets on noise. This guide walks through what large-scale data actually means, how scaling laws have evolved, and what your team needs to do differently to turn data volume into model quality.
Key Takeaways
| Point | Details |
|---|---|
| Size isn’t everything | Quality, governance, and balance matter as much as quantity for large-scale ML success. |
| Optimal ratios unlock performance | The Chinchilla law shows that data and model size must scale together for best results. |
| Operational pain points are real | Hardware, cost, and data sprawl must be actively managed to benefit from large datasets. |
| Scalable pipelines are critical | Modern methodologies and tools enable teams to automate, partition, and recover at scale. |
Defining large-scale data: Beyond the buzzwords
The term “large-scale data” gets used loosely. In a machine learning context, it has a specific meaning that goes well beyond what a single database or a laptop cluster can handle.
The 4Vs framework gives us a useful lens:
- Volume: Terabytes to zettabytes of raw data. Global data generation hit 149 zettabytes in 2024, and 41% of large enterprises now manage more than one petabyte of data actively.
- Velocity: Data that arrives continuously or near-continuously, think streaming sensor data, real-time user interactions, or web crawls running 24/7.
- Variety: Structured tables, unstructured text, images, audio, video, and semi-structured formats like JSON logs all coexisting in the same pipeline.
- Veracity: The reliability and accuracy of data. High volume with low veracity is not an asset. It is a liability.
It’s worth separating “big data” as an infrastructure concept from “ML large-scale data” as a training concern. Big data infrastructure (Hadoop, Spark) focuses on storage and processing. ML large-scale data strategy focuses on whether the data actually moves the model in the right direction. Understanding the true role of datasets in model success forces you to think about fitness for purpose, not raw size.
Here’s a quick reference for real-world dataset scales:
| Dataset | Domain | Scale |
|---|---|---|
| Visual Genome | Image understanding | 108k images, 5.4M region descriptions |
| Common Pile | Language modeling | Multi-terabyte public corpus |
| RamanBench | Scientific spectra | 325k labeled spectra |
| Internal web crawl | Domain-specific LLMs | Petabyte-range raw HTML |
What separates a strong training corpus from a large pile of files comes down to one thing: curation. Building a high-quality dataset means thinking through deduplication, labeling consistency, and domain coverage before you hit collect.
The evolution of scaling laws: Why size and quality both matter
With those characteristics in mind, it’s important to understand how much data, and what kind, actually drives today’s most successful AI models.

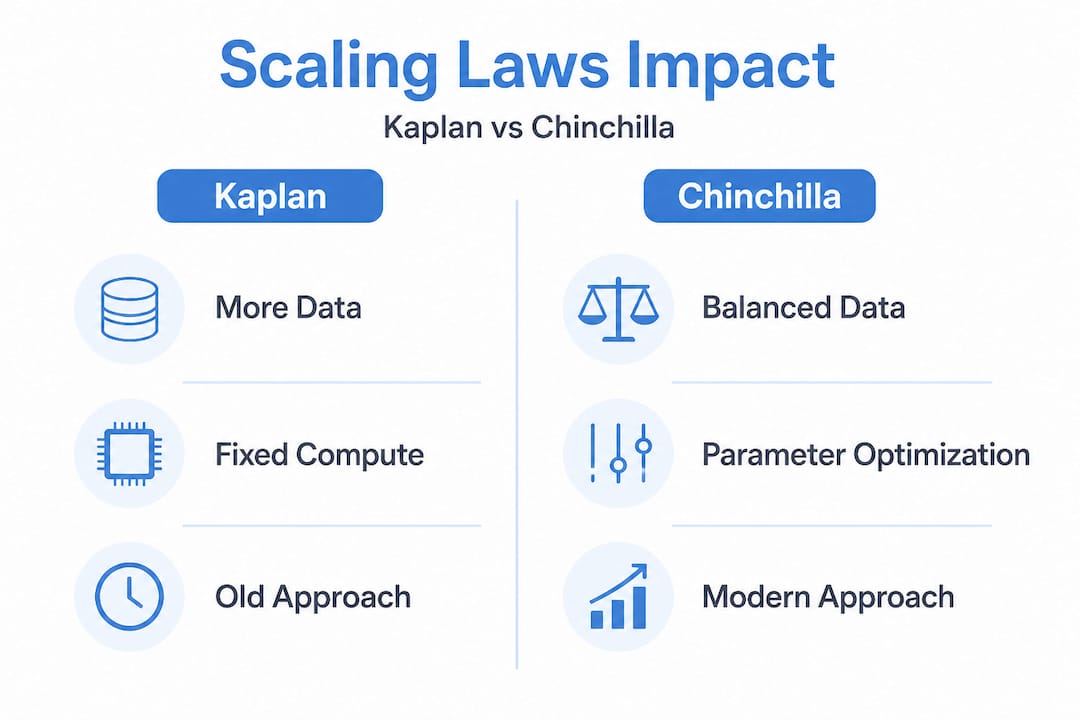
The dominant view for years followed Kaplan scaling laws, which suggested that if you had a fixed compute budget, you should spend it on making the model bigger rather than feeding it more data. Larger models, the logic went, would generalize better even with relatively less training data.
Chinchilla scaling upended that assumption. The core finding: for compute-optimal training, you should scale model parameters N and dataset size D roughly equally, targeting around 20 tokens per parameter. A 70 billion parameter model, for example, needs approximately 1.4 trillion training tokens to be Chinchilla-optimal.
The practical implications are significant:
- Smaller models trained on more, better-curated data can match or outperform larger models trained on less data.
- Data collection and curation become first-class engineering priorities, not afterthoughts.
- The Kaplan vs. Chinchilla contrast means teams that blindly scale parameters without matching data investment are likely leaving significant performance on the table.
For inference-heavy production workloads, the calculus shifts again. Larger models with less training data are sometimes preferred because inference cost favors a well-trained, smaller model. The right ratio depends entirely on your compute budget, latency requirements, and deployment context.
Pro Tip: Before scoping your next training run, calculate your Chinchilla-optimal token target based on your parameter count. If your current dataset falls short, invest in curation and collection rather than just growing model size. The optimal data volume question has a mathematical answer now. Use it.
Challenges in managing large-scale data
Understanding optimal size is only part of the challenge. The real work comes in execution, and at scale, execution failures are expensive.
Here are the most common failure modes:
- Hardware bottlenecks: At 10,000+ GPU scales, a 0.1% hourly failure rate means a hardware fault approximately every six minutes. Without checkpoint recovery, that means restarting multi-hour training runs repeatedly.
- GPU memory limits: Large batches and large models push into GPU memory ceilings fast. Mixed precision training (FP16 or BF16) is no longer optional; it is standard practice for any serious large-scale run.
- Data sprawl: As teams collect more data across more sources, governance breaks down. Files accumulate in object storage without clear lineage, duplicates multiply, and compliance risks grow. Data sprawl is both a cost problem and a regulatory risk.
- Quality degradation at scale: Poor-quality data does not become diluted as volume grows. It compounds. Common Pile demonstrates that reproducible, well-governed public datasets outperform unstructured web dumps in downstream benchmark performance, precisely because curation was taken seriously from the start.
“The dataset is not a sidecar to the model. It is the substrate on which the model’s capabilities are built. Every shortcut taken during collection shows up as a ceiling in production.”
Operational fault recovery is a particularly underappreciated problem. When a GPU node drops out mid-training, your pipeline needs sub-90-second recovery to maintain throughput. Without shadow loaders and robust checkpointing built into your data collection pipeline, you are running without a safety net.
Pro Tip: Implement a data governance policy before you scale collection, not after. Define retention rules, deduplication thresholds, provenance logging, and compliance review checkpoints at the start of the project. Retrofitting governance onto a 500-terabyte corpus is far more painful and costly than building it in from day one.
Best practices for scalable, high-quality data pipelines
To overcome these hurdles, robust pipeline strategies are essential. The good news is that the methodology is well-established, even if implementation requires discipline.
Here is a stepwise approach for teams building or improving large-scale data pipelines:
- Partition early and often. Use auto-partitioning loaders (tools like OVERLORD apply min-edge-cut graph partitioning via GREM to balance shard sizes and minimize cross-node communication). Balanced partitions reduce stragglers and improve GPU utilization across large clusters.
- Apply distributed data parallelism (DDP). DDP splits data across workers while keeping model replicas in sync. It scales well to thousands of GPUs when combined with gradient checkpointing and efficient collectives.
- Use aspect-ratio grouping for multimodal data. For vision and video datasets, grouping samples by aspect ratio before batching reduces padding overhead and speeds up iteration significantly.
- Build checkpoint and shadow loader redundancy. At extreme scales, 30 to 45% of training time is spent in collective operations. Sub-90-second fault recovery via shadow loaders and frequent checkpoints is what keeps large runs from becoming expensive failures.
- Validate continuously, not just at ingestion. Schema validation, label consistency checks, and statistical distribution monitoring should run throughout the pipeline, catching drift before it corrupts a training shard.
- Document lineage from source to model. Every dataset transformation, cleaning step, and labeling pass should be logged. This is not bureaucracy. It is the audit trail that lets you reproduce results and debug regressions.
Pro Tip: Apply training-ready data best practices as a checklist during pipeline design, not as a post-processing review. Teams that validate format, label quality, and deduplication upstream spend far less time debugging training instability downstream.
Our take: What most ML teams miss about large-scale data
After reviewing the methodology, here is a critical perspective that rarely makes it into best-practice guides.
Most ML teams treat data scaling as a logistics problem. Collect more, store more, process faster. What they miss is that data strategy is a modeling decision. The choices you make about what to collect, how to clean it, and what to exclude directly shape the hypothesis space your model can explore.
We have seen teams spend months collecting petabyte-scale web data, only to find their model underperforms a competitor’s version trained on a fraction of the volume but with far more intentional curation. The competitor did not have more data. They had better data for the specific task. Following AI dataset trends in 2026, the pattern is consistent: domain-specific, well-curated corpora are outperforming general-purpose data dumps across most fine-tuning benchmarks.
The uncomfortable truth is that curation requires judgment, and judgment requires domain expertise. Automated pipelines catch format errors. They do not catch subtle distributional biases, mislabeled edge cases, or systematic gaps in coverage. That requires human review at key quality gates, and that investment pays off far more reliably than adding another terabyte of unreviewed crawl data.
Three things ML leaders can act on right now:
- Audit your existing datasets against clear high-quality dataset criteria before expanding collection.
- Define a “minimum viable curation” standard for every data source entering your pipeline.
- Measure data quality metrics (deduplication rate, label agreement, coverage gaps) alongside model metrics. If your data quality dashboards are less detailed than your training loss curves, you have an inversion problem.
Petabytes do not equal progress. Fit-for-purpose data, delivered reliably, does.
How Dot Data Labs empowers your large-scale data journey
Turning the frameworks in this article into production-ready datasets is where most teams hit friction, whether from tooling gaps, vendor fragmentation, or internal bandwidth constraints.

DOT Data Labs handles the full data supply chain, from large-scale data collection and cleaning through labeling and validated delivery in model-ready formats. Whether you need a one-off custom dataset scoped to your exact specifications, an off-the-shelf corpus ready for immediate use, or a recurring data pipeline feeding your AI-driven model training infrastructure continuously, we scope every project against your data protection requirements before a single byte is collected. Explore our training-ready data best practices to see how we define quality at scale, and reach out to discuss your current data needs.
Frequently asked questions
What size is considered large-scale data for machine learning?
Large-scale datasets typically range from terabytes to zettabytes and exceed the processing capacity of standard single-node tools. The practical threshold depends on your infrastructure, but multi-terabyte corpora are widely considered large-scale for ML training purposes.
Why is data quality crucial in large-scale AI training?
Poor-quality data at scale causes overfitting and training instability, even when the raw volume looks impressive. Veracity, the fourth V, determines whether your data actually drives model improvement or just consumes compute.
How can ML teams efficiently manage large-scale data pipelines?
Distributed data parallelism, partitioned loaders with auto-balancing, and checkpoint-based fault recovery are the core techniques for managing data pipelines at scale. Building these in from the start, rather than retrofitting them, saves significant engineering time.
What are some common pitfalls when scaling data for AI?
The most frequent problems are hardware bottlenecks at GPU scale, data sprawl costs and compliance risks, and governance gaps that let low-quality data contaminate training corpora. Teams that skip governance during collection almost always pay for it during training.
What are examples of large-scale datasets used in AI?
Well-known examples include Visual Genome for image understanding (108k images, 5.4M region descriptions), the Common Pile as a reproducible public language corpus, and RamanBench with 325k labeled scientific spectra for domain-specific applications.