
What is a data pipeline? Unlock AI success in 2026

TL;DR:
- Most AI failures stem from data and pipeline issues, not the model architecture itself.
- Proper pipeline design, architecture choice, and monitoring are essential for reliable AI performance.
- Enhancing pipeline reliability can significantly boost end-to-end AI accuracy and outcomes.
Most AI teams blame their models when performance tanks. The real culprit is almost always upstream. ~80% of ML failures trace back to data and pipeline issues, not the model architecture itself. If you’re an ML engineer or AI startup founder, understanding data pipelines isn’t optional. It’s the difference between a model that ships and one that stalls in staging forever. This article breaks down what data pipelines are, how they’re structured, where they fail, and what the benchmarks actually say about their impact on end-to-end AI performance.
Key Takeaways
| Point | Details |
|---|---|
| Pipelines drive AI outcomes | Most model failures are due to data and pipeline issues, not algorithms. |
| Architecture choice matters | Selecting the right Lambda, Kappa, or Hybrid/Delta design shapes workflow efficiency and reliability. |
| Watch for silent failures | Edge cases like schema drift and training-serving skew can break pipelines without warning. |
| Benchmark for impact | Pipeline quality directly influences real-world AI accuracy, not just theoretical performance. |
Defining data pipelines: Core concepts and structure
A data pipeline is an automated sequence of steps that moves raw data from its source to a place where it can train a machine learning model or power a production AI system. Think of it as a factory assembly line. Raw materials go in one end, finished components come out the other. Except here, raw events and records become training-ready features.
The core stages of a well-designed pipeline include:
- Ingestion: Pulling data from APIs, databases, data lakes, or event streams
- Validation: Checking schema conformance, value ranges, and null rates before data moves forward
- Transformation: Cleaning, normalizing, and reshaping data into consistent formats
- Feature engineering: Creating model-ready signals from raw fields (ratios, embeddings, aggregations)
- Storage: Writing to feature stores, data warehouses, or vector databases
- Model training: Consuming features to fit or fine-tune the model
- Monitoring: Tracking data quality and model performance in production
The data preprocessing workflow at the start of a pipeline is more consequential than most teams realize. Errors introduced here compound through every downstream stage.
One critical design principle: training and serving must see the same features. When they don’t, you get training-serving skew, one of the most insidious failure modes in production ML. Continuous training pipelines handle feature engineering, model training, validation, and retraining automatically, using feature stores to keep training and inference consistent.
“A pipeline isn’t just plumbing. It’s the governance layer that determines whether your model learns what you intended it to learn.”
The other element that separates mature pipelines from ad hoc scripts is data curation for AI. Curation ensures that what enters the pipeline is relevant, representative, and appropriately labeled. Without it, even a perfectly engineered pipeline produces garbage outputs.
Getting dataset structuring for training right early is what separates teams that iterate quickly from teams that spend sprints debugging unexplained model degradation.
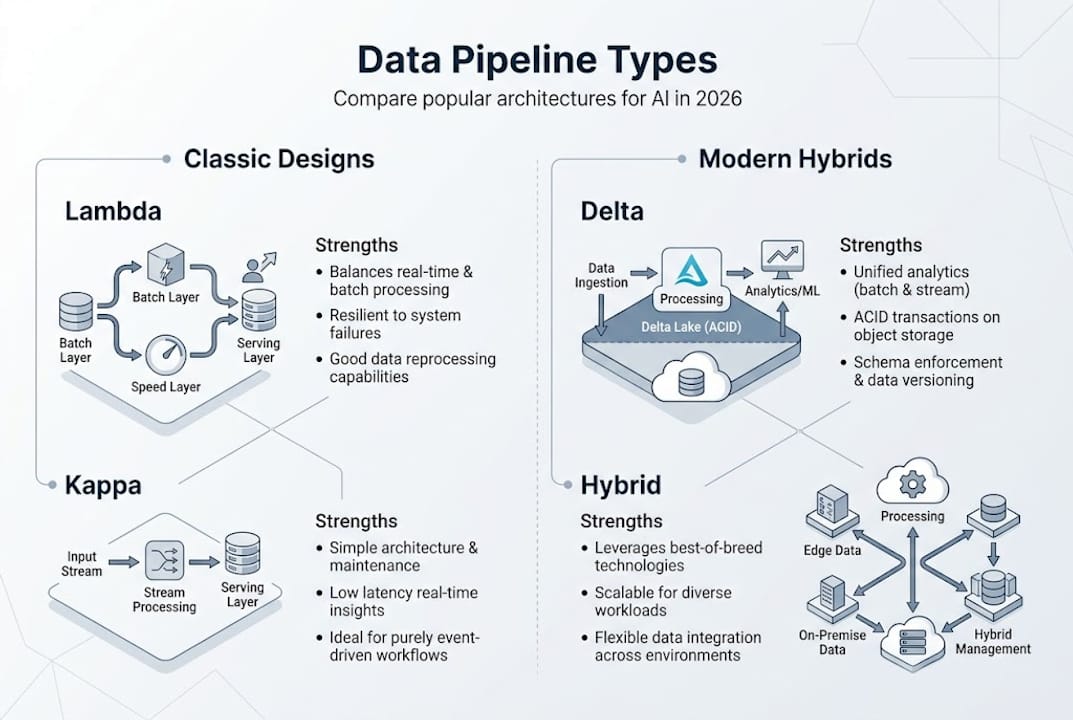
Common pipeline architectures: Lambda, Kappa, and Hybrid/Delta
Once you understand the components, the next decision is how to arrange them. Your choice of architecture shapes throughput, latency, and how much engineering overhead your team carries.
| Architecture | Best for | Key strength | Main weakness |
|---|---|---|---|
| Lambda | Mixed batch + real-time needs | High accuracy via dual processing paths | Complex to maintain two codebases |
| Kappa | Real-time streaming workloads | Simpler, unified codebase | Struggles with historical data reprocessing |
| Hybrid/Delta | Modern AI with mixed data demands | Balances flexibility, speed, and simplicity | Requires mature tooling to implement well |
Lambda architecture runs two parallel paths: a batch layer for accuracy and a speed layer for low latency. Results are merged before serving. This sounds elegant until your team has to maintain two separate processing codebases that must produce identical outputs. Divergence between the paths is a constant operational headache.

Kappa architecture simplifies this by treating everything as a stream. There’s one codebase, lower complexity, and faster iteration. But when you need to reprocess historical data, say, after fixing a bug in your feature logic, Kappa struggles. Replaying large historical event logs through a streaming system is slow and expensive.
Hybrid and Delta architectures have emerged as the pragmatic answer for AI teams. According to Lambda vs Kappa architecture analysis, Lambda offers accuracy through dual paths but carries high maintenance costs, Kappa is simpler for real-time but struggles with historical reprocessing, and hybrid or Delta designs balance both. Delta Lake, in particular, pairs well with ML workflows by providing ACID transactions and schema enforcement on top of object storage.
Pro Tip: If your AI system needs both real-time inference and periodic batch retraining, a Delta or hybrid approach will save your engineering team weeks of debugging caused by inconsistent feature values across layers.
Choosing the wrong architecture doesn’t just create technical debt. It directly impacts your model’s accuracy by introducing inconsistencies in how data is processed at different times. Pair your architecture choice with solid data structuring methods to avoid compounding errors downstream.
Why data pipelines fail: Bottlenecks and edge cases
Understanding pipeline architecture is useful, but anticipating where and why pipelines break is what separates operational teams from theoretical ones. The failure modes are rarely dramatic. Most are quiet, slow, and devastating.
Common pipeline failure points include:
- Data drift: Incoming data distribution shifts over time, causing models trained on historical data to degrade silently
- Schema changes: An upstream system adds, renames, or removes a field, and your pipeline breaks without warning
- Training-serving skew: Features computed during training differ from features computed at inference time
- Silent pipeline breaks: A job fails but doesn’t surface an error. Stale or missing data flows downstream undetected
- Latency collapse under load: A pipeline that handles normal traffic gracefully falls apart at scale
ML pipeline edge cases include data quality degradation, training-serving skew, schema mismatches, data drift, silent pipeline breaks, and latency collapse under load. Any one of these can render an otherwise excellent model useless in production.
“Silent failures are the most dangerous. Your model keeps predicting. Your dashboard stays green. But the predictions are quietly wrong.”
The debugging challenge is that these failures often look like model performance issues. A team will spend two weeks tuning hyperparameters before someone checks whether the feature pipeline was even writing correct values. Avoid those dataset pitfalls by building validation checks into every stage, not just at ingestion.
Pro Tip: Treat your data pipeline like production software. Version your schemas, write unit tests for transformation logic, and set up anomaly detection on feature distributions. Most teams skip this until after their first major production incident.
Building reliable AI model evaluation practices also helps here. Golden datasets give you a stable reference point to detect when pipeline changes have altered feature behavior. They’re one of the most underused tools in the ML engineer’s toolkit. ML system failures show that even great models crumble when the pipeline feeding them is unreliable.
Data pipelines in action: AI/ML workflow impact and empirical benchmarks
Theory aside, let’s talk numbers. Pipeline quality has a measurable, quantified impact on what AI systems can actually achieve.
The KramaBench study examined AI system performance on data-intensive tasks. The results are sobering. AI systems achieved only 50% end-to-end accuracy on data-intensive tasks, and even with perfect retrieval conditions, performance topped out at 59%. The gap between retrieval and execution reveals something important: the bottleneck is not finding the data. It’s processing it reliably through the pipeline.
| Condition | End-to-end accuracy |
|---|---|
| Standard pipeline execution | ~50% |
| Perfect retrieval provided | ~59% |
| Gap from pipeline execution weakness | ~9 percentage points |
This benchmark matters for your team because it confirms that pipeline execution quality, not just data availability, limits what your AI system can do. You can have a great model and clean data and still underperform because the pipeline connecting them is fragile.
To improve your AI data benchmarks and real-world accuracy, focus on these steps:
- Tighten integration between retrieval and processing layers so feature computation is consistent and verifiable
- Build feedback loops that flag when pipeline outputs diverge from expected distributions
- Validate end-to-end using held-out test sets that mirror production conditions, not just offline benchmarks
- Monitor inference-time features separately from training-time features to catch skew early
- Instrument your pipeline with detailed logging so failures surface immediately, not after model decay is noticed
Understanding the role of datasets in this context means recognizing that a dataset’s value is inseparable from the pipeline that delivers it. A perfectly labeled dataset fed through a broken pipeline is wasted investment.
A fresh take: Why pipelines, not just data or models, define AI outcomes
Here’s the uncomfortable reality that most teams don’t want to hear: obsessing over data quality and model architecture while ignoring pipeline maturity is like tuning a race engine while the fuel line leaks.
We’ve seen AI teams spend months collecting and labeling data, then burn that investment by rushing the pipeline. Feature versioning is skipped. Schema validation is an afterthought. Monitoring gets added after the first production fire. The result is a model that looked great in development and quietly underperforms in the real world.
The KramaBench findings reinforce this. Fine-grained data-dependent reasoning limits end-to-end success more than retrieval failures. The pipeline execution layer is where AI ambitions meet engineering reality. Retrieval from data lakes is challenging but is not the primary bottleneck. Execution is.
The real leverage comes from investing in observability, schema governance, and feedback loops before you have a production problem. Teams that treat pipelines as first-class infrastructure, not just glue code, compound their advantages over time. Every improvement to pipeline reliability multiplies the value of your data and model investments simultaneously.
If you want to understand what structured datasets in ML actually require to perform at scale, start by auditing your pipeline. The answers are usually there.
Next steps: Data pipeline solutions for winning AI
You now have a clear map of what data pipelines are, how they fail, and why they determine the ceiling on your AI system’s performance. The next step is building on that foundation with production-grade datasets and pipeline-ready structure.

At DOT Data Labs, we produce large-scale, structured datasets built for AI workflows. Every dataset we deliver is schema-consistent, deduped, and formatted for direct use in training, fine-tuning, or RAG pipelines. Our dataset optimization guide gives you a practical framework to maximize model accuracy from your data investment. If you’re ready to stop fighting your pipeline and start shipping better models, DOT Data Labs is built for exactly that.
Frequently asked questions
What does a data pipeline do in machine learning?
A data pipeline automates data flow from ingestion through feature engineering to model training, ensuring consistent, repeatable AI workflows. Continuous training pipelines also handle retraining and use feature stores to keep training and serving consistent.
What causes most data pipeline failures in AI?
Common failures include data drift, schema mismatches, training-serving skew, and silent breakdowns where jobs fail without alerting downstream consumers. Pipeline edge cases also include latency collapse under load.
How do different pipeline architectures affect AI outcomes?
Lambda, Kappa, and Hybrid/Delta architectures each balance speed, flexibility, and maintenance costs differently, directly affecting how consistently features reach your model. Lambda vs Kappa tradeoffs are especially relevant for teams with both batch and real-time needs.
Why is pipeline performance crucial for AI accuracy?
Benchmarks show that even with perfect data retrieval, end-to-end AI accuracy caps at 59% on data-intensive tasks, revealing pipeline execution as the binding constraint on model performance.