
Streamline dataset deduplication for better AI model quality

TL;DR:
- Duplicate data skews model training and inflates benchmark scores, with deduplication improving performance significantly.
- Effective deduplication involves hashing for exact duplicates and fuzzy matching like MinHash LSH for near-duplicates.
- Combining deduplication with quality upsampling enhances model accuracy more than simply adding raw data.
Duplicate data is one of the most underestimated threats to model performance. It hides in plain sight across your training corpus, silently skewing loss curves, inflating benchmark scores, and training your model to memorize rather than generalize. Benchmarks show MinHash/LSH best overall for LLM pretraining, with effective deduplication improving model performance equivalent to adding 30 to 50% more unique data. This guide walks through the complete deduplication workflow: why it matters, what tools you need, how to execute each stage, and how to verify real downstream gains.
Key Takeaways
| Point | Details |
|---|---|
| Structured workflow boosts model accuracy | Following a four-stage deduplication pipeline can enhance AI model performance by up to 50 percent. |
| Choose the right tools for scale | GPU or disk-optimized frameworks like FED and LSHBloom enable deduplication at massive scales efficiently. |
| Quality matters more than size | Strategic repetition of top examples may outperform simply maximizing dataset uniqueness. |
| Measure, iterate, verify | Benchmark deduplication with precision, recall, and F1, then connect to downstream accuracy or model ROI. |
Understanding dataset deduplication: Why it matters
Duplicates are not just an aesthetic problem. When the same text, record, or example appears multiple times in a training dataset, your model doesn’t treat it as noise. It treats it as signal. Repeated patterns get overweighted, causing the model to memorize specific examples rather than learning robust generalizations. This shows up as inflated training accuracy, poor generalization on held-out sets, and brittle performance in production.
There are two main types of duplicates you need to handle:
- Exact duplicates: Byte-for-byte identical records. Caught efficiently with MD5 or SHA hash comparisons.
- Near-duplicates: Documents or records that are semantically or textually similar but not identical. Paraphrased content, scraped articles with minor edits, or records with different formatting but equivalent meaning all fall into this category. These require fuzzy matching techniques like MinHash LSH.
The performance stakes are real. Benchmarks show MinHash/LSH best overall for LLM pretraining, demonstrating that proper deduplication can deliver gains equivalent to 30 to 50% more unique training data. That’s a meaningful efficiency gain, especially when data amount for ML is often a bottleneck for startups operating under compute and budget constraints.
“Deduplication doesn’t just shrink your dataset. Done correctly, it rebalances the learning signal so the model spends its capacity learning meaningful patterns rather than replicating noise.”
One counterintuitive finding worth flagging early: pure removal is not always the right strategy. Deduplication not always pure removal is a documented research outcome, where quality-based upsampling or strategic repetition of the best unique documents actually outperforms simply throwing more raw data at the problem. We’ll come back to this in the perspective section.
What you need for effective deduplication
Before you run a single deduplication job, you need the right infrastructure in place. The tools, compute resources, and pipeline position all determine whether your deduplication pass is effective or wasted effort.
Core tools by use case:
| Tool | Best for | Scale |
|---|---|---|
| MD5/SHA hashing | Exact deduplication | Any |
| MinHash + LSH | Near-duplicate fuzzy matching | Millions to billions |
| Apache Spark | Distributed deduplication at scale | Billions+ |
| Faiss | Embedding-based similarity search | Large corpora |
| Duplodocus | Disk-based, memory-constrained pipelines | Billions |
| LSHBloom | Fast, low-disk-footprint deduplication | Large-scale streaming |
Compute requirements vary significantly by data scale. For datasets under a few million records, a single powerful CPU node is sufficient. Once you pass tens of millions of records, you’ll want distributed frameworks or GPU-accelerated tools. The expert nuances documented in Duplodocus recommend integrating deduplication into your ETL pipeline after extraction and initial filtering, but before any training-ready formatting or labeling.

The positioning in your data transformation for AI workflow matters enormously. Running deduplication too early means you haven’t filtered low-quality records yet, so you’re comparing noise to noise. Running it too late means you’ve already wasted compute embedding or labeling duplicate content.
A critical architectural decision: sharded versus global deduplication. Sharded approaches split your data into partitions and deduplicate within each shard independently. This is faster and easier to parallelize, but it misses cross-shard duplicates. Global deduplication catches everything but requires more coordination and memory. For most AI startup pipelines processing hundreds of gigabytes to a few terabytes, a hybrid approach works best: global exact deduplication first (cheap and fast), followed by sharded near-duplicate removal.
Also, consider your dataset cleansing steps before deduplication. If your records haven’t been normalized for whitespace, encoding, or case, you’ll miss exact duplicates that hash differently due to superficial formatting differences.
Pro Tip: For streaming data pipelines or incremental dataset updates, implement deduplication incrementally using a persistent hash index or Bloom filter. This prevents you from re-deduplicating the entire corpus every time new data arrives, which saves significant compute at scale. ML integration in business pipelines increasingly rely on this pattern for real-time data quality management.
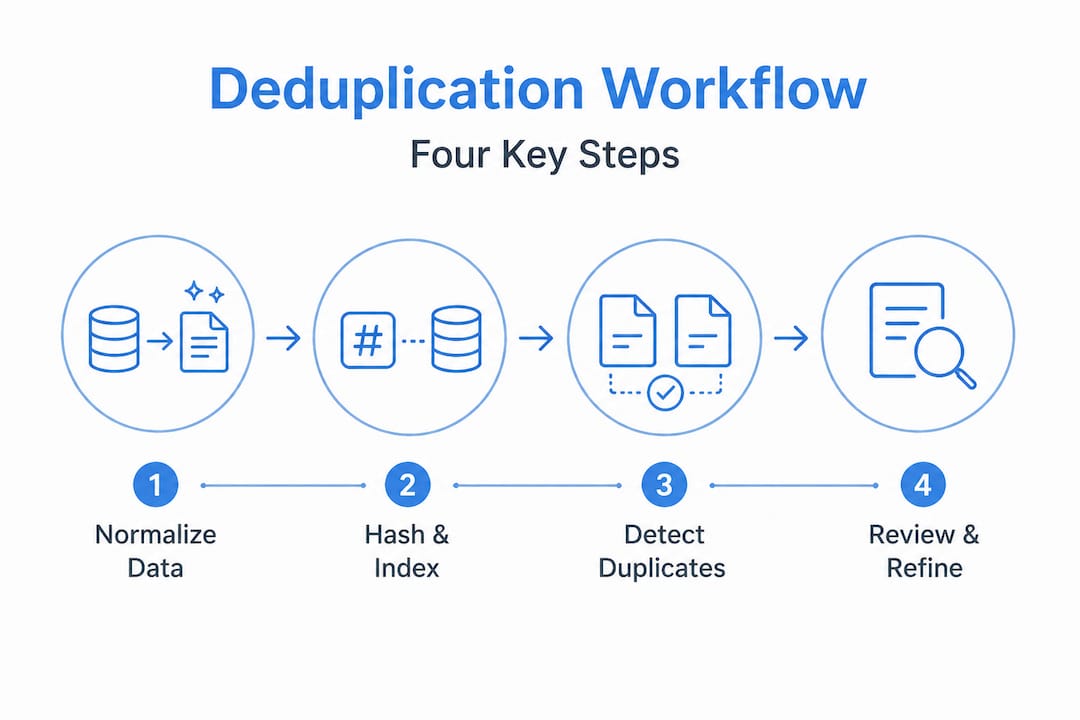
Step-by-step workflow for dataset deduplication
The standard workflow for dataset deduplication in ML pipelines follows four well-defined stages. Understanding what happens inside each stage lets you tune and debug your pipeline rather than treating it as a black box.
The four-stage deduplication pipeline:
-
Compute representations. Transform each record into a comparable form. For exact deduplication, compute MD5 or SHA256 hashes of normalized text. For near-deduplication, generate MinHash signatures using character n-grams. For semantic deduplication, generate dense embeddings using a sentence encoder.
-
Index and find candidate pairs. Use Locality Sensitive Hashing (LSH) to bucket records with similar signatures together, so you only compare candidates that are likely duplicates. This avoids the O(n²) comparison problem that makes naive deduplication impossible at scale.
-
Cluster candidates. Apply a union-find (disjoint set) algorithm to cluster all connected duplicates into groups. Each cluster represents a set of records that are duplicates of one another.
-
Filter and output unique data. From each cluster, select one representative record (typically the longest, the highest-quality score, or the first seen) and discard the rest.
Comparison of deduplication methods:
| Method | Speed | Recall | Best use case |
|---|---|---|---|
| Exact hash (MD5/SHA) | Very fast | Perfect for identicals | Removing copied records |
| MinHash LSH | Fast at scale | High for near-dups | Web-crawled or scraped text |
| Embedding similarity | Slow | Best for semantics | Paraphrase and concept dups |
Exact deduplication uses hashing (MD5/SHA) for identical records, while fuzzy near-duplicate detection uses MinHash LSH to approximate Jaccard similarity through shingling, signature computation, and banding.
Parameter tuning for MinHash LSH is where most teams leave performance on the table. MinHash LSH parameters that work well in practice: n-grams of 5, num_perm between 128 and 256, with bands of 14 to 20 and rows of 5 to 8, targeting a Jaccard similarity threshold around 0.8. Lowering the threshold catches more near-duplicates but increases false positives. Raising it is safer but misses subtle duplicates.
When building your deduplication pipeline from scratch, the create high-quality ML datasets framework is a useful reference point. Connecting deduplication to your broader data preprocessing workflow ensures your deduplication results feed cleanly into downstream normalization and labeling stages.
Pro Tip: For batch scenarios, run global exact dedup first, then shard your data for MinHash near-dedup. For streaming, maintain a persistent LSH index and check incoming records against it before insertion. This hybrid approach handles both speed and coverage without full re-processing.
Verifying and scaling deduplication for model impact
Deduplication without verification is just hope. You need to measure whether your pipeline is actually removing the right records and whether those removals translate into better model performance.
What to measure:
- Precision: Of the pairs flagged as duplicates, how many actually are duplicates? Low precision means false removals, which can hurt coverage.
- Recall: Of all true duplicate pairs, how many did your pipeline catch? Low recall means duplicates survive into training.
- F1 score: The harmonic mean of precision and recall, giving a balanced view of deduplication quality.
- Downstream model metrics: Perplexity, accuracy on held-out sets, generalization benchmarks. These are the ultimate validation that your deduplication is helping rather than hurting.
Benchmarks show MinHash/LSH best overall for LLM pretraining, with precision ranging from 0.833 to 0.985 and recall from 0.247 to 0.989 across different languages and domains. The variance in recall highlights why parameter tuning matters for your specific dataset characteristics.
For datasets at the billion-record scale, standard single-node MinHash pipelines break down. For large-scale deduplication: Use distributed tools like Spark, GPU-accelerated FED (which delivers up to 107x speedup over CPU), disk-based Duplodocus for memory-constrained environments, or LSHBloom, which runs 12x faster and uses 18x less disk than standard MinHashLSH implementations.
A real-world deduplication effectiveness case study illustrates how removing near-duplicate records before fine-tuning can dramatically reduce training time while simultaneously improving generalization. The compounding effect is significant: smaller, cleaner datasets train faster, checkpoint more efficiently, and deliver sharper results on evaluation sets. For further reading on how clean data feeds into model architecture decisions, the dataset structuring for LLMs resource covers the downstream implications in detail.
Our expert perspective: When deduplication is not just about deletion
Here’s the view that most practitioners miss: deduplication is a quality control strategy, not a data reduction strategy. Treating it purely as “remove duplicates, get cleaner data” is an oversimplification that can lead to underperforming models.
Deduplication not always pure removal is a finding from recent research showing that quality-based upsampling, strategically repeating your best unique documents rather than uniformly expanding your corpus, consistently outperforms brute-force data addition. For AI startups, this reframes the entire deduplication decision. The question isn’t just “what should I remove?” It’s “what should I keep, and how many times?”
The practical implication: after deduplication, score your remaining unique records for quality using signals like source authority, linguistic complexity, or task relevance. Then upsample the top-scoring records by a factor of 2x to 7x. This pattern is referenced in LLM data structuring insights as a key lever for teams that can’t easily acquire more raw data.
The counterintuitive takeaway is that a 10 million record dataset with thoughtful deduplication and upsampling can outperform a 50 million record raw corpus on downstream task performance. More data without quality control is just more noise. Smart deduplication combined with quality-aware repetition is how leading teams get more out of what they already have.
Enhance your AI data quality with Dot Data Labs
At DOT Data Labs, deduplication isn’t an afterthought. It’s built into every dataset production pipeline we run.

If your team is building LLM fine-tuning datasets, RAG corpora, or structured training sets for vertical AI systems, we can help you get there faster. Our AI production dataset structure framework covers schema design, deduplication logic, entity resolution, and training-ready formatting in one end-to-end workflow. Explore our dataset optimization guide for a deeper look at how we approach data quality, or review our ML dataset structuring techniques to see how structured, deduplicated datasets translate directly into better model outcomes.
Frequently asked questions
What is the fastest way to find duplicates in large datasets?
GPU-accelerated frameworks like FED or LSHBloom drastically speed up deduplication, with FED achieving up to 107x faster processing versus traditional CPU methods for massive datasets.
How do you measure deduplication effectiveness?
Effectiveness is assessed using precision, recall, and F1 score against known duplicate pairs, then validated by improvements in downstream model metrics like perplexity and held-out accuracy. MinHash/LSH benchmarks show precision up to 0.985 and recall up to 0.989 for the best configurations.
When should deduplication be done in the ML workflow?
Deduplication should run after extraction and initial quality filtering, before training-ready formatting or labeling. For streaming pipelines, expert nuances from Duplodocus recommend incremental deduplication using persistent indexes to avoid full re-processing on each update.
Is removing all duplicates always best?
Not always. Deduplication not always pure removal shows that strategic repetition of the highest-quality unique examples can improve model accuracy better than unfiltered inclusion of larger raw datasets. Quality-aware upsampling after deduplication often yields the best training outcomes.