
Smart data extraction for reliable AI training datasets

TL;DR:
- Raw OCR data alone is insufficient for effective ML training because it produces unstructured streams lacking schema and validation. Smart data extraction converts documents into schema-aligned, validated records with layout understanding, significantly improving downstream model performance. Ensuring rigorous validation and monitoring at each stage prevents silent errors, enabling scalable, high-quality AI data pipelines.
Raw text from a document scanner is not training data. That distinction matters more than most ML teams realize until a model trained on OCR output starts failing silently on structured tasks. Smart data extraction goes well beyond plain text recognition: it produces schema-aligned, labeled, validated records that downstream training pipelines can actually consume. This guide breaks down what that means in practice, walks through the architecture of a modern extraction pipeline, explains why validation is non-negotiable, and flags the edge cases that quietly wreck data quality even when automation metrics look fine.
Key Takeaways
| Point | Details |
|---|---|
| Goes beyond OCR | Smart data extraction includes structure, context, and validation so AI workflows get usable, schema-rich data. |
| Built for ML reliability | Output data is schema-aligned, field-validated, and ready for direct use in model training pipelines. |
| Validation prevents errors | Automated checks for conformance and correctness catch mistakes before they harm model performance. |
| Watch for edge cases | Template changes or visual noise can lead to invisible errors, so vigilance and testing are essential. |
What smart data extraction really means
OCR reads characters off a page. That is all it does. It gives you a stream of tokens with no awareness of whether a number belongs in a price field, a date column, or a footnote. For downstream AI tasks, that output is nearly useless without heavy post-processing.
Smart data extraction is the process of converting documents into structured, labeled records with schema-aligned fields, correct data types, and validated relationships. Think JSON objects where every key maps to a known field in your training schema, not a flat text dump you then have to parse manually. The difference in downstream productivity is enormous.
Consider a financial document pipeline. OCR gives you “4,200.00” somewhere in a wall of text. Smart extraction gives you "{“line_item”: “Invoice Total”, “amount”: 4200.00, “currency”: “USD”, “confidence”: 0.97}`. That record plugs directly into a training dataset without a single line of hand-written parsing code.
The core capabilities that separate smart extraction from basic OCR include:
- Layout detection: Identifies tables, headers, footers, columns, and multi-column layouts
- Field mapping: Assigns extracted values to the correct schema fields using positional and semantic signals
- Key-value pairing: Extracts labeled pairs even when document templates vary
- Table extraction: Reconstructs row-column relationships into usable arrays
- Validation and typing: Enforces data types, ranges, and format rules at the field level
These capabilities matter because AI structuring methods require clean, typed, schema-conformant input, and the gap between “we ran OCR” and “we have training-ready records” is where most extraction projects fail. Understanding why structured data drives model performance helps clarify why this investment in extraction quality pays dividends during fine-tuning and evaluation.
“Structure is not a post-processing step. It is the extraction goal.”
Inside a modern smart data extraction pipeline
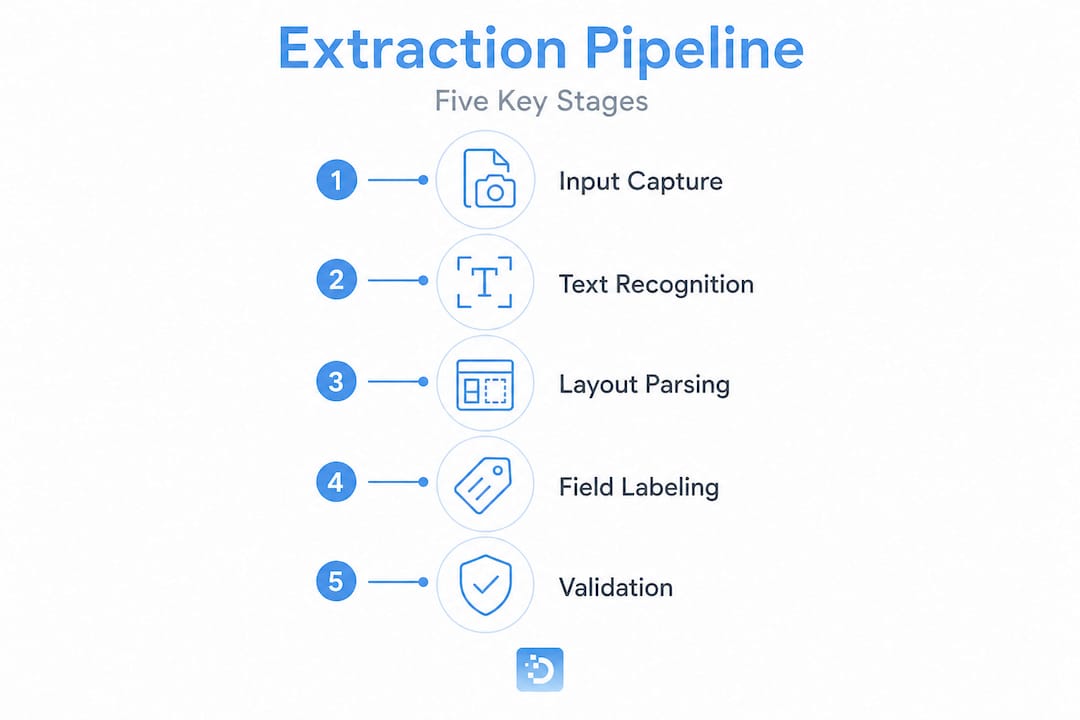
To implement reliable extraction at scale, you need to understand the full stack. A modern pipeline is not a single model. It is a sequence of specialized components, each responsible for a specific transformation, with handoffs between them.
Here is how the stages typically look:
- Text recognition (OCR layer): Converts image or PDF content to raw text with bounding box coordinates
- Layout detection: Identifies structural elements: tables, figures, form fields, sections
- NLP tagging: Applies named entity recognition and semantic classification to raw tokens
- Field mapping: Aligns tagged tokens to a predefined output schema
- Confidence scoring: Assigns extraction confidence per field to flag low-certainty values
- Error validation: Checks schema conformance, numeric tolerances, required fields, and relational consistency
Modern extraction pipelines combine all of these components, with layout-aware modeling and NLP working together to produce usable structured output. The critical insight is that each stage reduces a different class of error. OCR handles recognition errors. Layout detection handles structural ambiguity. NLP handles semantic misclassification. Validation catches everything the upstream stages missed.
| Capability | Basic OCR pipeline | Smart extraction pipeline |
|---|---|---|
| Text recognition | Yes | Yes |
| Layout-aware parsing | No | Yes |
| NLP field classification | No | Yes |
| Schema-aligned output | No | Yes |
| Field-level confidence | No | Yes |
| Automated validation | No | Yes |
| Output format | Plain text | JSON, XML, CSV |
The table makes the gap obvious. A basic OCR pipeline handles one job. A smart pipeline handles six, each of which contributes to better LLM training outcomes and keeps your machine-ready dataset aligned with your actual schema.
Pro Tip: Run your pipeline against a held-out document set that includes intentionally difficult layouts, such as rotated tables and multi-column forms, before scaling. Problems that appear at 1% frequency in a 10,000-document run become major issues at 10 million records.
Accuracy, validation, and error detection: Going beyond ‘good enough’
An extraction number like “98% accuracy” sounds reassuring. It is not, unless you know what that metric covers. If it is token-level character accuracy, you could still have 30% of your numeric fields wrong due to misclassification or structural errors. Field-level accuracy is the only metric that matters for ML training datasets.

Correctness must be validated at the field level, covering schema conformance, numeric tolerance, and detection of both omissions and hallucinated values. That last category, hallucinations, is frequently underestimated. An extraction model can confidently produce a plausible-looking value for a field that does not exist in the source document. Without a validation layer that checks for grounding, that fabricated value enters your training set as a clean label.
The validation metrics your pipeline should track include:
- Schema conformance rate: Percentage of records that match expected field structure
- Numeric tolerance compliance: Fields where extracted numbers fall within acceptable range of ground truth
- Null/omission detection rate: How often the system correctly flags absent fields rather than hallucinating values
- Confidence calibration: Whether high-confidence scores actually correlate with correctness
- Cross-field consistency: Relational checks, such as line item totals matching subtotals
Real-world example: A numeric field for invoice amounts should have a tolerance threshold, say plus or minus 0.01, to account for rounding. Array fields like line items need alignment validation to confirm that row count and column structure match the schema. If your pipeline is not checking these relationships, silent mismatches accumulate.
Your AI data quality checklist should treat field-level validation as a hard requirement, not an optional enhancement. And your extraction pipeline checklist should include explicit test cases for each validation rule before any data moves to a training job.
Pro Tip: Build a validation failure log that records not just failure counts but failure patterns. If the same field type fails repeatedly under the same layout conditions, you have a systematic problem, not a random error.
Common pitfalls and challenges in smart data extraction
Advanced extraction tools create a false sense of security. When automation handles millions of documents without visible errors, teams naturally reduce human review cycles. That is precisely when silent errors accelerate.
Edge cases including visual noise and document template changes can produce hallucinated or mis-mapped values that go completely undetected without robust validation. The most damaging failure modes are not crashes or obvious errors. They are records that look correct but carry wrong values.
The specific challenges to monitor in production include:
- Template drift: Vendors, partners, or internal teams change document layouts without notifying the data team, breaking field mappings silently
- Visual noise: Stamps, watermarks, and scan artifacts that confuse layout models
- Schema mismatch: Upstream schema changes that the extraction config has not caught up with
- Confidence score decay: A pipeline whose confidence scores stop correlating with actual accuracy as document distribution shifts
- Hallucinated fields: Plausible-looking values generated for fields absent in the source document
- Low-volume edge cases: Document subtypes that appear rarely in QA but frequently in production
“The data debt you accumulate from undetected extraction errors is always paid, eventually, in degraded model performance and expensive re-annotation.”
Your high-quality ML dataset guide should include ongoing monitoring as a first-class concern, not a post-deployment afterthought. Production pipelines need drift detection, not just launch-time validation.
Beyond the hype: Why smart extraction is a strategic enabler for ML teams
Most conversations about smart data extraction focus on the tooling. Better models, faster throughput, higher automation rates. Those things matter, but they are not the strategic point. The strategic point is repeatability.
A model trained on unvalidated extraction output is built on an unstable foundation. Every time the extraction pipeline silently changes its behavior, the training data shifts. You end up debugging model regressions that trace back to data quality issues that were never caught because nobody was watching the extraction layer.
What separates high-performing ML teams from teams stuck in re-annotation cycles is not the quality of their extraction models. It is the rigor of their validation and correction workflows. Knowing how to format training-ready data correctly is table stakes. The teams who win are the ones who treat training-ready data criteria as a system-level requirement with ongoing enforcement, not a one-time launch checklist.
Configuration drift is the most underestimated risk. Field mappings that worked perfectly against your initial document set will degrade as real-world document diversity grows. Teams that schedule regular extraction audits, validate against a representative held-out set, and track per-field accuracy over time are the teams that maintain model quality at scale. The ones who skip that discipline end up with training datasets that require expensive retroactive cleaning.
Scale your AI data extraction with Dot Data Labs
If this guide has clarified what good extraction actually requires, the next question is whether your current setup can deliver it at the scale your training roadmap demands.

At DOT Data Labs, we handle the full extraction and structuring pipeline: sourcing, scraping, cleaning, field-level validation, human annotation, and final delivery in model-ready formats. From one-off custom dataset builds to ongoing real-time pipelines, we have delivered projects including a 32 million science Q&A dataset in under 30 days. Our extraction pipeline checklist is one starting point; our AI-driven model training solutions take you the rest of the way. Talk to us about what your data pipeline actually needs.
Frequently asked questions
How is smart data extraction different from OCR?
Smart extraction converts documents into schema-aligned, validated structured records rather than raw text strings, producing output that is directly usable for AI model training without additional parsing.
Why is validation so crucial in smart data extraction for ML?
Validation ensures every extracted field matches schema requirements and correct value ranges, preventing silent errors like hallucinated values or mis-mapped fields from contaminating training datasets and degrading model performance.
What are the main challenges of smart data extraction in production?
Visual noise and template drift are the most common sources of silent data debt, producing plausible-looking but incorrect field values that bypass basic accuracy checks.
How does smart extraction impact AI model performance?
Models trained on smart-extracted data receive clean, typed, schema-aligned labels rather than fragmented OCR output, which directly improves generalization and reduces the annotation rework that typically follows poor extraction quality.
Which output formats are typical for smart-extracted data?
The most common output formats are JSON, XML, and CSV, each structured for direct ingestion into ML training pipelines without additional transformation steps.