
AI-Ready Datasets: How to Accelerate Machine Learning

TL;DR:
- Most AI project failures originate from poor data quality rather than flawed models.
- Ensuring datasets meet measurable quality metrics across seven dimensions is crucial for reliable AI performance.
- Continuous validation and disciplined data workflows prevent costly mistakes and support scalable, trustworthy AI deployment.
Most AI projects don’t fail because of bad models. They fail because of bad data. 67% of AI projects collapse due to data quality issues before a single hyperparameter gets tuned. If you’re an ML engineering manager or data scientist, you’ve likely felt this friction firsthand: months of pipeline work, a promising architecture, and then results that simply don’t hold up. This guide breaks down exactly what makes a dataset truly AI-ready, how quality metrics connect to model outcomes, and how to build a workflow that prevents costly failures before they happen.
Key Takeaways
| Point | Details |
|---|---|
| Quality trumps quantity | Smaller, cleaner datasets often produce more accurate AI models than large noisy ones. |
| Follow clear metrics | Use defined criteria like completeness, consistency, and timeliness to assess dataset readiness. |
| Implement a robust workflow | A stepwise process—profiling, cleansing, transforming, validating—produces reliable, AI-ready data. |
| Continuously check for pitfalls | Ongoing validation and awareness of biases or edge cases protect you from silent failures. |
What makes a dataset AI-ready?
Not every dataset that exists in a database or data lake is ready for machine learning. AI-ready means the data meets a defined set of measurable quality criteria that allow a model to learn reliably, generalize well, and perform consistently in production. Understanding high-quality dataset criteria is the foundation every ML team needs before sourcing or building training data.
The core quality metrics for AI-readiness break down into seven dimensions:
| Quality Metric | Definition | Target Threshold |
|---|---|---|
| Completeness | No missing values in critical fields | >99% for critical fields |
| Consistency | Uniform formats across all records | Zero format conflicts |
| Accuracy | Data reflects real-world ground truth | Validated against source |
| Timeliness | Data freshness meets training SLAs | Defined per use case |
| Uniqueness | No duplicate records | Full deduplication |
| Representativeness | Coverage across all relevant subgroups | Balanced class distribution |
| FAIR compliance | Findable, Accessible, Interoperable, Reusable | Documented metadata |
Each metric plays a distinct role. Completeness gaps in critical fields mean your model trains on partial information, which creates systematic blind spots. Consistency failures, like dates stored in three different formats across the same dataset, force the model to learn noise rather than signal. Accuracy is arguably the most dangerous metric to neglect: if your labels don’t reflect reality, your model learns to predict the wrong thing with high confidence.
Representativeness deserves special attention. A dataset that over-represents one demographic, language, or scenario will produce a model that performs well in testing and fails in production when it encounters real-world diversity. FAIR compliance matters most for teams working across organizations or regulatory environments, ensuring that data can be traced, reused, and audited.
How data quality metrics impact AI performance
Knowing the metrics is the first step. Seeing their direct effect on model outcomes is what makes them actionable.
Quality data yields 15 to 30% accuracy gains, and structured datasets improve both training speed and accuracy by 20 to 25%. These aren’t marginal improvements. On a production model where a 2% accuracy gain means millions in revenue or avoided risk, a 20% improvement is transformational.

Here’s how each dimension connects to real model behavior:
| Quality Dimension | Effect on Model | Consequence of Failure |
|---|---|---|
| Completeness | Enables full feature utilization | Imputation errors, biased predictions |
| Consistency | Reduces preprocessing noise | Feature encoding failures |
| Accuracy | Aligns model to ground truth | High-confidence wrong predictions |
| Representativeness | Improves generalization | Bias in production outputs |
| Uniqueness | Prevents overfitting to duplicates | Inflated evaluation metrics |
One of the most counterintuitive findings in applied ML is that smaller clean datasets outperform larger, noisier ones. Teams often assume more data is always better. In practice, a 500,000-record dataset with 15% label noise can underperform a 100,000-record dataset that has been rigorously cleaned and validated. The model spends its capacity learning the noise rather than the signal.
Reviewing an AI data quality checklist before training runs is one of the highest-leverage habits an ML team can build. It takes less time than a single failed training run and prevents far more expensive mistakes downstream.
Pro Tip: Always validate for representativeness before training, not after. Running a class distribution check and a demographic coverage audit at the profiling stage catches bias before it gets baked into model weights. Fixing bias post-training is expensive. Preventing it is cheap.
The teams that consistently produce strong model results are the ones optimizing datasets for accuracy as a deliberate, structured step rather than an afterthought. They treat structuring data for AI as engineering work, not data janitorial work.
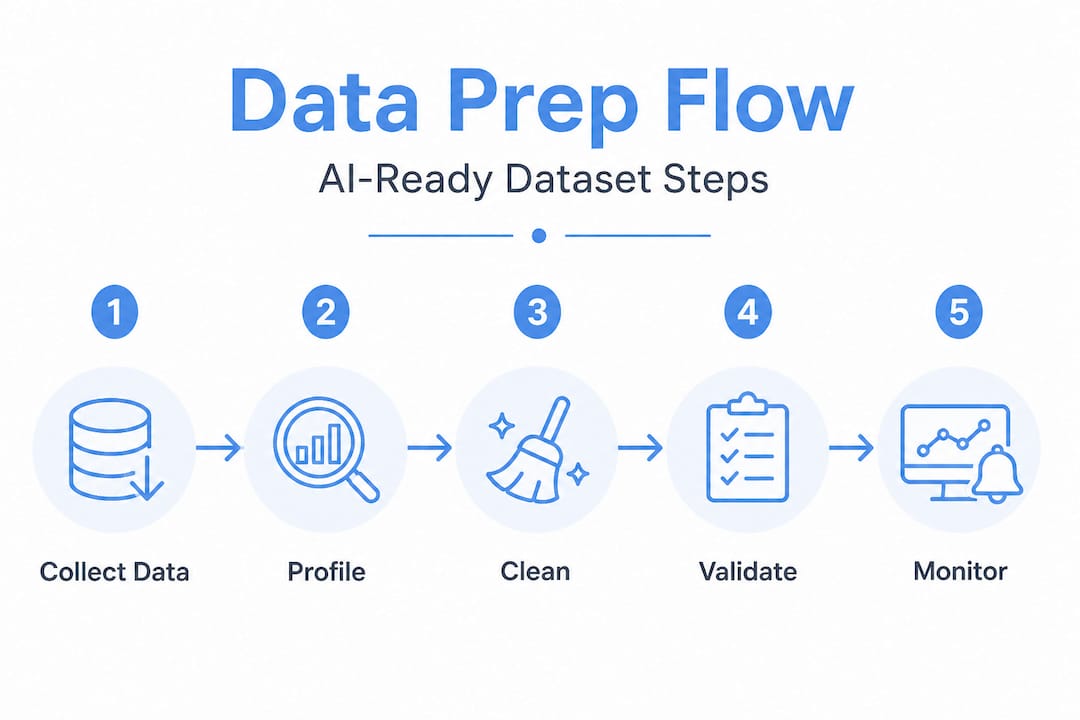
Workflow for building and assessing AI-ready datasets
After grasping why quality matters, here’s how to actually create and trust production-grade datasets. A structured workflow removes ambiguity and gives your team a repeatable process that scales.
“Structured datasets improve training speed and accuracy by 20 to 25%. The difference between a team that ships models and a team that iterates endlessly often comes down to how disciplined their data preparation process is.”
The five-stage workflow for building AI-ready datasets:
-
Audit: Inventory all data sources. Identify origin, format, licensing, and any regulatory constraints. Flag sources that may introduce compliance risk before any collection begins.
-
Profiling: Run automated statistical analysis across all fields. Check for missing values, distribution skew, format inconsistencies, and outliers. This is where dataset curation tips pay off most directly, because early detection of problems is exponentially cheaper than late detection.
-
Cleansing: Remove duplicates, fix format inconsistencies, handle missing values with documented strategies, and validate labels against ground truth. The dataset cleansing process should be version-controlled and reproducible, not a one-off script that only one engineer understands.
-
Transformation: Convert data into the schema and format your model expects. This includes tokenization for NLP tasks, normalization for numerical features, and encoding for categorical variables. Document every transformation so the pipeline can be audited later.
-
Validation: Run a final quality gate against your defined thresholds. Completeness above 99% for critical fields. Zero format conflicts. Deduplication confirmed. Representativeness verified. Only data that passes validation moves to training. This step is where core quality metrics become operational checkpoints rather than abstract ideals.
Continuous assessment matters as much as the initial build. Data drift, where the statistical properties of incoming data shift over time, is one of the most common causes of silent model degradation. A model that performed at 94% accuracy at launch can quietly drop to 81% six months later if no one is monitoring the data feeding it.
Pro Tip: Automate profiling at every stage of your pipeline. Set threshold alerts that trigger a review when distributions shift beyond a defined tolerance. This turns data quality from a launch-time concern into an ongoing operational practice.
Pitfalls to avoid when preparing datasets
Even with a solid workflow, some mistakes consistently trip up experienced teams. Knowing them in advance is the difference between a smooth launch and a painful post-mortem.
-
Mixing raw and processed data: Storing raw source data alongside cleaned training data in the same location creates version confusion and makes it impossible to reproduce results reliably. Keep them strictly separated with clear versioning.
-
Ignoring edge cases and rare labels: Models trained without sufficient representation of rare classes will fail precisely when rare events matter most. If your fraud detection model never trained on a specific fraud pattern because it appeared in only 0.1% of records, it will miss it in production.
-
Feature and label leakage: Leakage occurs when information that wouldn’t be available at prediction time gets included in training features. It produces artificially high evaluation metrics that collapse in production. Audit your feature construction logic carefully.
-
Overlooking representativeness: A dataset collected from a single region, time period, or user segment will encode those biases directly into your model. Review classification dataset best practices to understand how to structure balanced, diverse training sets.
-
Treating validation as a one-time event: Data changes. Sources change. Business definitions change. A dataset that was AI-ready at collection may not be AI-ready six months later.
Pro Tip: When you’re debating whether to collect more data or clean what you have, clean first. Smaller clean datasets consistently outperform larger noisy ones. More data is only valuable when the data is trustworthy.
Why most teams underestimate the challenge of AI-ready data
Here’s the uncomfortable truth most teams learn the hard way: data readiness is not a checklist you complete once. It’s an ongoing discipline that requires the same engineering rigor as your model architecture.
Most organizations treat data preparation as a precursor to the “real work” of AI development. The model is the product. The data is just fuel. This framing is exactly backwards. The role of datasets in prediction is not supporting. It’s foundational. Your model is only as good as the distribution it learned from.
When AI projects fail, the post-mortem almost always traces back to a data assumption that was never validated. A label definition that was inconsistently applied. A source that introduced systematic bias. A time window that leaked future information into training features. These aren’t model problems. They’re data problems that look like model problems until you dig deep enough.
67% of AI projects fail due to data issues. That number should reframe how your team allocates time and budget. If most failures are data failures, then most of your quality investment should be in data, not in model tuning.
The teams that consistently ship reliable AI products treat data readiness as a first-class engineering concern. They build pipelines, not one-off scripts. They validate continuously, not just at launch. They invest in data infrastructure the same way they invest in compute.
Accelerate your AI with production-ready datasets
If your team is ready to break past common barriers and deliver results, the fastest path forward is working with data that’s already been sourced, cleaned, labeled, and validated to production standards.

At DOT Data Labs, we handle the full data supply chain so your team can focus on modeling. Whether you need better data for smarter AI through an off-the-shelf dataset, a custom one-off build scoped to your exact specifications, or an ongoing data pipeline that feeds your training infrastructure continuously, we deliver production-grade output at scale. We recently delivered a 32 million science Q&A dataset in under 30 days. Every dataset we build is validated against criteria for training-ready data before it reaches your team. Explore our production-ready datasets and see what’s possible when data quality is treated as a core deliverable.
Frequently asked questions
What defines a dataset as AI-ready?
A dataset is AI-ready when it meets strict quality metrics including completeness above 99% for critical fields, consistent formatting, accurate labels, timely updates, full deduplication, representative coverage, and FAIR compliance. Meeting all seven dimensions is what separates training-ready data from raw data that looks usable.
Does dataset size or cleanliness matter more?
Cleanliness matters more. Smaller clean datasets consistently outperform larger noisy ones because models learn from signal, not volume. Prioritize quality validation before scaling collection.
What is the impact of poor-quality data on AI models?
Poor-quality data is the primary driver of AI project failure, accounting for 67% of failures before model or algorithm errors even become relevant. Bad data produces confident but wrong predictions that are difficult to diagnose.
How often should datasets be validated for AI use?
Datasets should be validated continuously, not just at initial build. Any data update, source change, or schema modification should trigger a fresh quality check against your defined quality thresholds to confirm ongoing AI-readiness.
Recommended
- Machine-Ready Dataset Guide: Build Optimized AI Training Sets – Dot Data Labs – High-Quality Data for Training AI Models
- AI-driven model training: Better data, smarter results
- What is training-ready data? Criteria and best practices
- Master the role of datasets in prediction for AI
- AI-Powered Digital Marketing and App Development Services