
AI data pipeline: optimize model training end-to-end

TL;DR:
- Most ML pipelines struggle with data quality, validation, and reproducibility rather than ingestion speed. Ensuring each stage is deliberately designed improves model reliability, monitoring, and continuous retraining. Focusing on validation, versioning, and modular orchestration prevents degraded performance and enhances AI pipeline success.
Most ML teams discover the hard way that their biggest pipeline bottleneck isn’t ingestion speed. It’s quality, validation, and reproducibility. You can pour raw data into your training infrastructure at scale, but if the transformation and validation stages are weak, your models learn from noise instead of signal. The result? Training runs that look fine on paper but produce models that fail in production. Understanding what each pipeline stage actually does, and how to design them intentionally, is the difference between shipping reliable models and chasing data bugs for weeks.
Key Takeaways
| Point | Details |
|---|---|
| End-to-end pipeline stages | A robust AI data pipeline covers ingestion, transformation, governance, serving, and feedback for continuous improvement. |
| Ensure validation and quality | Building training-ready datasets requires thorough validation and quality checks at every stage. |
| Leverage modular workflows | Using DAGs and CI-CD enables modular, scalable AI pipelines that are reproducible and efficient. |
| Monitor and retrain proactively | Continuous monitoring and feedback loops help detect drifting or errors and trigger timely retraining. |
| Real-world accuracy challenges | Even best-performing AI pipelines may achieve only 50–60% end-to-end accuracy due to complexity and edge case failures. |
Core stages of the AI data pipeline
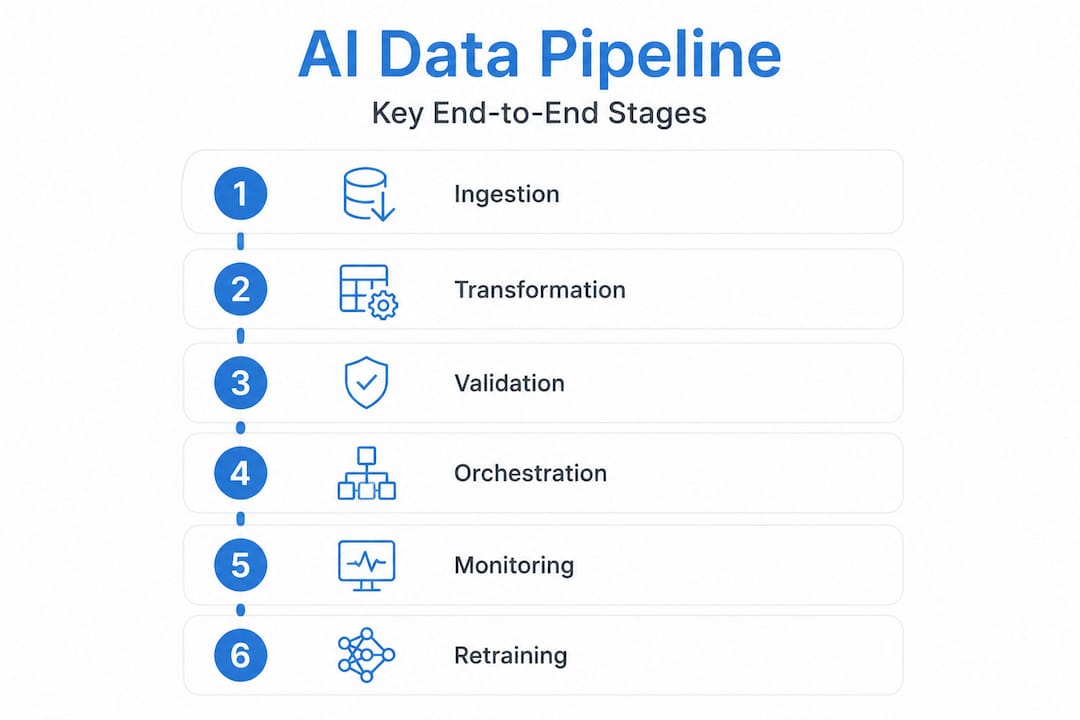
Before you can optimize anything, you need a clear map. A well-designed data pipeline breakdown is not a single step. It is a series of connected stages, each adding a layer of structure and reliability to your data.
According to the framework described in this end-to-end guide, an AI data pipeline is an end-to-end system that moves data from sources to model-ready form, typically including ingestion, transformation, cleaning, feature preparation, governance, lineage, serving, and feedback loops for continuous improvement. Each stage feeds the next, and a failure in any one of them ripples forward.
Here is a quick breakdown of each stage’s role:
- Ingestion: Pulling raw data from APIs, databases, web sources, or file stores
- Transformation: Cleaning, normalizing, mapping, and structuring data into usable formats
- Governance: Tracking data lineage, enforcing schemas, and ensuring compliance
- Serving: Delivering features and datasets to training jobs, with consistent formats
- Feedback loop: Capturing model performance signals to inform retraining
How does this differ from a traditional data pipeline? The comparison is instructive:
| Dimension | Traditional data pipeline | AI data pipeline |
|---|---|---|
| Primary goal | Move data to reports or dashboards | Produce model-ready training datasets |
| Transformation focus | Aggregation and formatting | Feature engineering and label alignment |
| Quality standards | Schema conformance | Labeling accuracy, class balance, drift detection |
| Lifecycle model | Batch, periodic updates | Continuous feedback and retraining cycles |
| Output consumer | BI tools, analysts | Training jobs, model serving infrastructure |
An AI data pipeline is not just a data movement system. It is a continuous improvement engine where every stage is designed to raise the quality of your training signal, not just the volume of your data.
This framing matters for decision-making. Teams that treat AI pipelines like traditional ETL (extract, transform, load) processes tend to underinvest in transformation and validation, which is exactly where most model quality problems originate.
Transformation and validation: preparing model-ready data
Building on those five stages, the transformation and validation steps deserve specific attention because they directly determine what your model actually learns.

Transformation covers a broad range of operations. Raw data almost never arrives in a format that a model can consume directly. You need to handle missing values, normalize numeric ranges, encode categorical variables, align timestamps, and map labels to consistent taxonomies. Feature preparation goes a step further, engineering derived signals that carry predictive value beyond what raw fields contain.
As Databricks outlines, AI data transformation steps often produce structured, analysis-ready outputs for ML and can be automated at scale. Automation here is not about cutting corners. It is about making the process repeatable and less vulnerable to human inconsistency across large datasets.
Validation is where most teams underinvest. It is not enough to transform data correctly once. You need quality gates that check:
- Label accuracy: Are annotations consistent and correctly aligned with the underlying data?
- Data integrity: Are there unexpected nulls, duplicates, or schema violations?
- Class balance: Is the distribution of labels appropriate for the training objective?
- Relevance: Does the data actually represent the real-world conditions the model will encounter?
Titannet’s pipeline guide confirms that training readiness checks should cover relevance, labeling quality, validation gates, and versioned organization for reproducibility. Dataset versioning is often treated as an afterthought, but it is critical. Without it, you cannot reproduce a training run six months later or compare model performance across different data cuts.
For teams looking to go deeper, the resources on data transformation for AI and data preprocessing best practices cover these mechanics in practical detail.
Pro Tip: Version your datasets with the same rigor you apply to model checkpoints. Store metadata alongside each version: source, collection date, preprocessing steps, and label schema. This makes debugging model regressions much faster.
Orchestration and modularity: DAGs, CI-CD, and scalable workflows
Once your data is transformed and validated, you need an orchestration layer that ties all stages together reliably. This is where DAGs (directed acyclic graphs) and CI-CD (continuous integration and continuous delivery) principles come in.
As Sandgarden explains, AI pipelines implemented as DAGs allow steps to be modular, parallelizable, and reproducible. Instead of a single monolithic script that runs start-to-finish, a DAG breaks the pipeline into discrete nodes, each with defined inputs, outputs, and dependencies. If a node fails, you can rerun just that step without reprocessing everything upstream.
The practical benefits include:
- Define your data contract first. Document expected schemas and formats before writing any pipeline code.
- Break each stage into an independent module. Ingestion, transformation, validation, and serving should each be separate, testable units.
- Assign explicit dependencies. Your DAG should encode which steps depend on which, so the orchestrator can parallelize safely.
- Apply CI-CD practices. Treat pipeline code like application code: version it, test it, deploy it through automated pipelines.
- Log every execution. Capture inputs, outputs, and runtime metrics for each node to make debugging faster.
Here is a simplified view of how a typical workflow maps out:
| Step | Function | Depends on |
|---|---|---|
| Ingestion | Pulls raw data from sources | None |
| Cleaning | Removes nulls, deduplicates | Ingestion |
| Feature engineering | Builds derived signals | Cleaning |
| Validation | Runs quality checks | Feature engineering |
| Dataset export | Packages model-ready output | Validation |
The pipeline extraction checklist is a useful starting point for teams designing this layer from scratch.
Continuous monitoring, retraining, and feedback loops
Orchestration sets up the foundation. Continuous monitoring keeps the pipeline trustworthy over time. This is where many production pipelines quietly degrade without anyone noticing.
The core problems to monitor for include data drift (input distributions shift), label drift (class prevalence changes), schema drift (source fields change unexpectedly), and training-serving skew (preprocessing behaves differently between training and production). As MLOps practitioners know, continuous monitoring with retraining triggers via drift detection or other signals is a standard best practice for mature AI pipelines.
Key monitoring practices worth implementing:
- Automated alerting when input distributions shift beyond defined thresholds
- Scheduled data quality reports comparing new batches against baseline statistics
- Retraining triggers that fire when model performance metrics drop below acceptable levels
- Lineage tracking to identify which data version was used for which model checkpoint
The accuracy challenge is real. KramaBench research shows that even best-performing systems may achieve only around 50 to 60 percent end-to-end pipeline execution accuracy for data-intensive agentic workflows. That gap between 60 percent and production-ready performance is where monitoring and feedback loops earn their value.
For practical guidance on applying these principles, the articles on accelerating machine learning and LLM fine-tuning data quality are directly relevant to teams building retraining workflows.
Pro Tip: Design your retraining process before you need it. Identify upfront what signals will trigger a retrain, what data will feed it, and how long it should take. Reactive retraining almost always becomes a bottleneck.
The uncomfortable truth: why most AI data pipelines disappoint in practice
Here is what years of working on production pipelines consistently reveals: the tools are not the problem. Most teams have access to excellent orchestration frameworks, monitoring platforms, and transformation libraries. The problem is that modularity and automation cannot replace deliberate quality planning.
Teams often treat validation as the last step, a checkbox before shipping. But schema drift, inconsistent preprocessing, and distribution shift are the edge cases that most commonly break production pipelines. None of these are tool failures. They are design failures.
The uncomfortable pattern we see repeatedly: teams build sophisticated orchestration, deploy beautiful DAGs, then discover that no node in the graph was explicitly responsible for checking whether the data still reflects reality. The pipeline runs successfully and produces garbage.
Good pipeline design means treating dataset cleansing insights and validation not as pipeline hygiene tasks but as first-class engineering concerns. They need owners, SLAs, and explicit success criteria, just like any other service your team operates.
A modular pipeline without explicit validation contracts is just a fast way to produce bad data at scale. Automation amplifies whatever quality decisions you made in the design phase.
Decision-makers who focus on training readiness over pipeline throughput consistently ship better models. Speed matters, but only after quality is locked in.
How Dot Data Labs supports efficient, high-quality AI pipelines
Putting these principles into practice takes more than a good architecture diagram.

DOT Data Labs handles the full data supply chain so your team can focus on modeling rather than pipeline engineering. From understanding what training-ready data looks like to deploying scalable batch and real-time pipelines, the team covers ingestion, cleaning, labeling, validation, and delivery in model-ready formats. Recent projects include a 32 million science Q&A dataset delivered in under 30 days and 50,000 hours of annotated video processed for AI training. For teams that need reliable data without building internal tooling from scratch, better AI model training starts with a partner who owns every stage of the pipeline.
Frequently asked questions
What are the key stages of an AI data pipeline?
The main pipeline stages are ingestion, transformation, governance, serving, and feedback loops that collectively turn raw data into model-ready datasets.
How does validation in AI data pipelines improve training results?
Validation checks enforce labeling quality, data relevance, and integrity standards so models learn from accurate, representative data rather than noisy or mislabeled inputs.
What challenges do organizations face in end-to-end AI pipeline execution?
End-to-end pipeline accuracy for data-intensive workflows can be as low as 50 to 60 percent, largely due to edge cases like schema drift, preprocessing inconsistencies, and distribution shift.
Why are DAGs used in AI data pipeline orchestration?
DAG-based pipelines enable modular, parallelizable, and reproducible workflows that scale more reliably and recover from failures more gracefully than monolithic pipeline scripts.
What is training-serving skew and why does it matter?
Training-serving skew occurs when preprocessing differs between training and production, causing models to behave differently at inference time than they did during validation, which quietly degrades production accuracy.